XDiT
xDiT: A Scalable Inference Engine for Diffusion Transformers (DiTs) with Massive Parallelism
Install / Use
/learn @xdit-project/XDiTREADME
- 🔥 Meet xDiT
- 📢 Open-source Community
- 🎯 Supported DiTs
- 📈 Performance
- 🚀 QuickStart
- 🖼️ ComfyUI with xDiT
- ✨ xDiT's Arsenal
- 📚 Develop Guide
- 🚧 History and Looking for Contributions
- 📝 Cite Us
Diffusion Transformers (DiTs) are driving advancements in high-quality image and video generation. With the escalating input context length in DiTs, the computational demand of the Attention mechanism grows quadratically! Consequently, multi-GPU and multi-machine deployments are essential to meet the real-time requirements in online services.
<h3 id="meet-xdit-parallel">Parallel Inference</h3>To meet real-time demand for DiTs applications, parallel inference is a must. xDiT is an inference engine designed for the parallel deployment of DiTs on a large scale. xDiT provides a suite of efficient parallel approaches for Diffusion Models, as well as computation accelerations.
The overview of xDiT is shown as follows.
<picture> <img alt="xDiT" src="https://raw.githubusercontent.com/xdit-project/xdit_assets/main/methods/xdit_overview.png"> </picture>-
Sequence Parallelism, USP is a unified sequence parallel approach proposed by us combining DeepSpeed-Ulysses, Ring-Attention.
-
PipeFusion, a sequence-level pipeline parallelism, similar to TeraPipe but takes advantage of the input temporal redundancy characteristics of diffusion models.
-
Data Parallel: Processes multiple prompts or generates multiple images from a single prompt in parallel across images.
-
CFG Parallel, also known as Split Batch: Activates when using classifier-free guidance (CFG) with a constant parallelism of 2.
The four parallel methods in xDiT can be configured in a hybrid manner, optimizing communication patterns to best suit the underlying network hardware.
As shown in the following picture, xDiT offers a set of APIs to adapt DiT models in huggingface/diffusers to hybrid parallel implementation through simple wrappers. If the model you require is not available in the model zoo, developing it by yourself is not so difficult; please refer to our Dev Guide.
We also have implemented the following parallel strategies for reference:
- Tensor Parallelism
- DistriFusion
Cache method, including TeaCache, First-Block-Cache and DiTFastAttn, which exploits computational redundancies between different steps of the Diffusion Model to accelerate inference on a single GPU.
<h3 id="meet-xdit-perf">Computing Acceleration</h3>Optimization is orthogonal to parallel and focuses on accelerating performance on a single GPU.
First, xDiT employs a series of kernel acceleration methods. In addition to utilizing well-known Attention optimization libraries, we leverage compilation acceleration technologies such as torch.compile and onediff.
The following open-sourced DiT Models are released with xDiT in day 1.
<h2 id="support-dits">🎯 Supported DiTs</h2> <div align="center">



| Model Name | CFG | SP | PipeFusion | TP | MR* | Performance Report Link | | --- | --- | --- | --- | --- | --- | --- | | 🎬 StepVideo | NA | ✔️ | ❎ | ✔️ | ❎ | Report | | 🎬 HunyuanVideo | NA | ✔️ | ❎ | ❎ | ✔️ | Report | | 🎬 HunyuanVideo-1.5 | ❎ | ✔️ | ❎ | ❎ | ✔️ | NA | | 🎬 ConsisID-Preview | ✔️ | ✔️ | ❎ | ❎ | ❎ | Report | | 🎬 CogVideoX1.5 | ✔️ | ✔️ | ❎ | ❎ | ❎ | Report | | 🎬 Mochi-1 | ✔️ | ✔️ | ❎ | ❎ | ❎ | Report | | 🎬 CogVideoX | ✔️ | ✔️ | ❎ | ❎ | ❎ | Report | | 🎬 Latte | ❎ | ✔️ | ❎ | ❎ | ❎ | Report | | 🎬 Wan2.1 | ❎ | ✔️ | ❎ | ❎ | ✔️ | NA | | 🎬 Wan2.2 | ❎ | ✔️ | ❎ | ❎ | ✔️ | NA | | 🎬 LTX-2 | ❎ | ✔️ | ❎ | ❎ | ✔️ | NA | | 🔵 HunyuanDiT-v1.2-Diffusers | ✔️ | ✔️ | ✔️ | ❎ | ❎ | Report | | 🔴 Z-Image Turbo | ❎ | ✔️ | ❎ | ❎ | ✔️ | NA | | 🟠 Flux 2 klein | ❎ | ✔️ | ❎ | ❎ | ✔️ | NA | | 🟠 Flux 2 | ❎ | ✔️ | ❎ | ❎ | ✔️ | NA | | 🟠 Flux | NA | ✔️ | ✔️ | ❎ | ✔️ | Report | | 🟠 Flux Kontext | ❎ | ✔️ | ❎ | ❎ | ✔️ | NA | | 🟢 Qwen Image | ❎ | ✔️ | ❎ | ❎ | ✔️ | NA | | 🟢 Qwen Image-Edit | ❎ | ✔️ | ❎ | ❎ | ✔️ | NA | | 🔴 PixArt-Sigma | ✔️ | ✔️ | ✔️ | ❎ | ❎ | Report | | 🟢 PixArt-alpha | ✔️ | ✔️ | ✔️ | ❎ | ❎ | Report | | 🟠 Stable Diffusion 3 | ✔️ | ✔️ | ✔️ | ❎ | ✔️ | Report | | 🟤 SANA | ✔️ | ✔️ | ✔️ | ❎ | ❎ | Report | | ⚫ SANA Sprint | NA | ✔️ | ❎ | ❎ | ❎ | NA | | 🟣 SDXL | ✔️ | ❎ | ❎ | ❎ | ❎ | NA |
MR* = Model is runnable via the model runner. If not, it's runnable via the provided example scripts.
</div> <h2 id="comfyui">🖼️ TACO-DiT: ComfyUI with xDiT</h2>ComfyUI, is the most popular web-based Diffusion Model interface optimized for workflow. It provides users with a UI platform for image generation, supporting plugins like LoRA, ControlNet, and IPAdaptor. Yet, its design for native single-GPU usage leaves it struggling with the demands of today's large DiTs, resulting in unacceptably high latency for users like Flux.1.
Using our commercial project TACO-DiT, a close-sourced ComfyUI variant built with xDiT, we've successfully implemented a multi-GPU parallel processing workflow within ComfyUI, effectively addressing Flux.1's performance challenges. Below is an example of using TACO-DiT to accelerate a Flux workflow with LoRA:
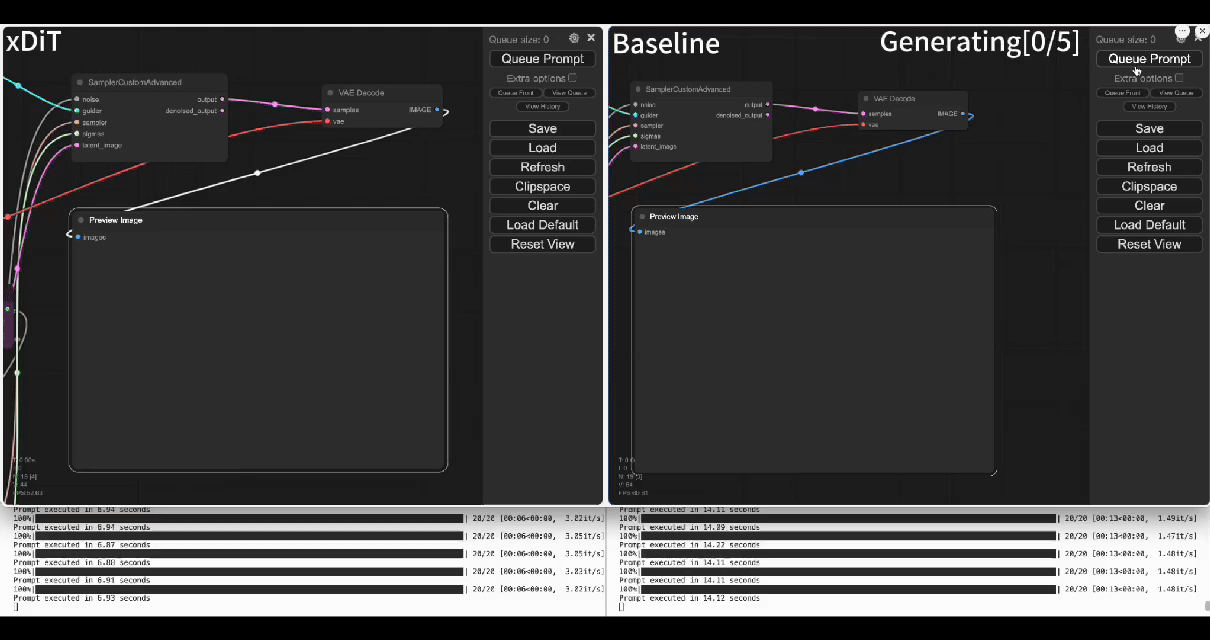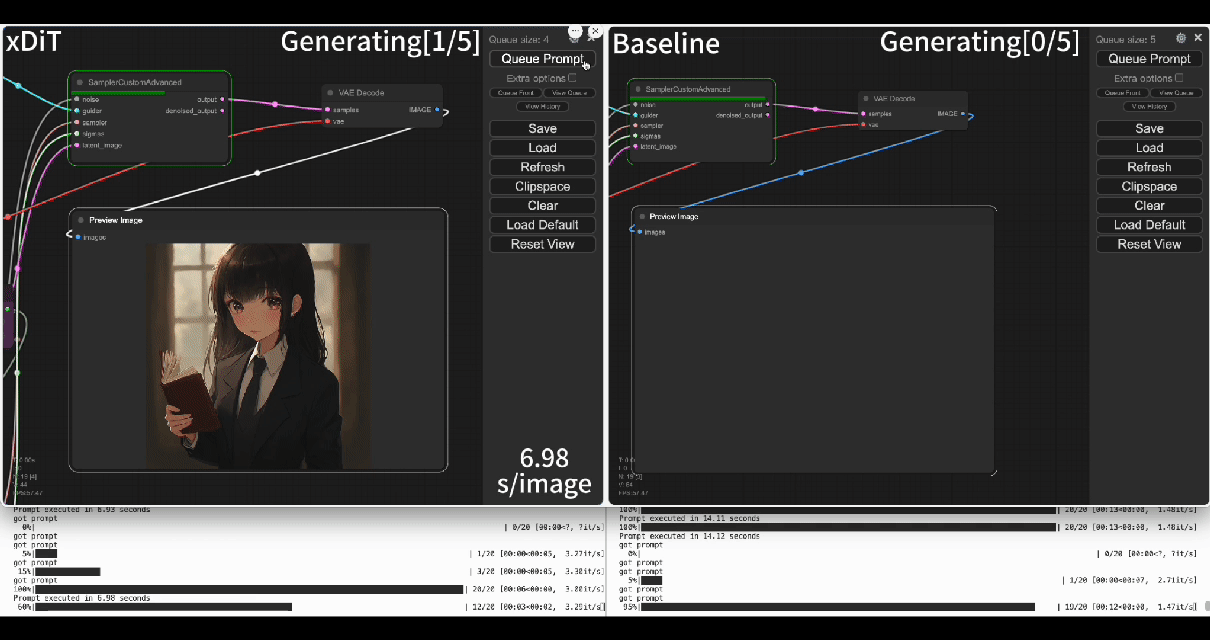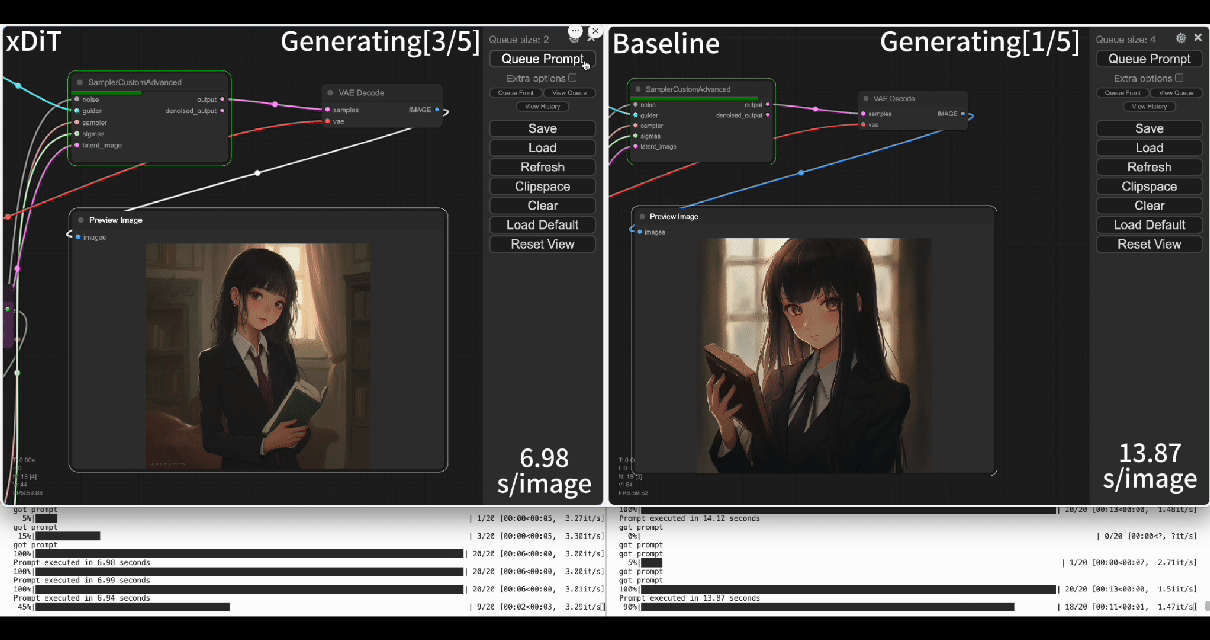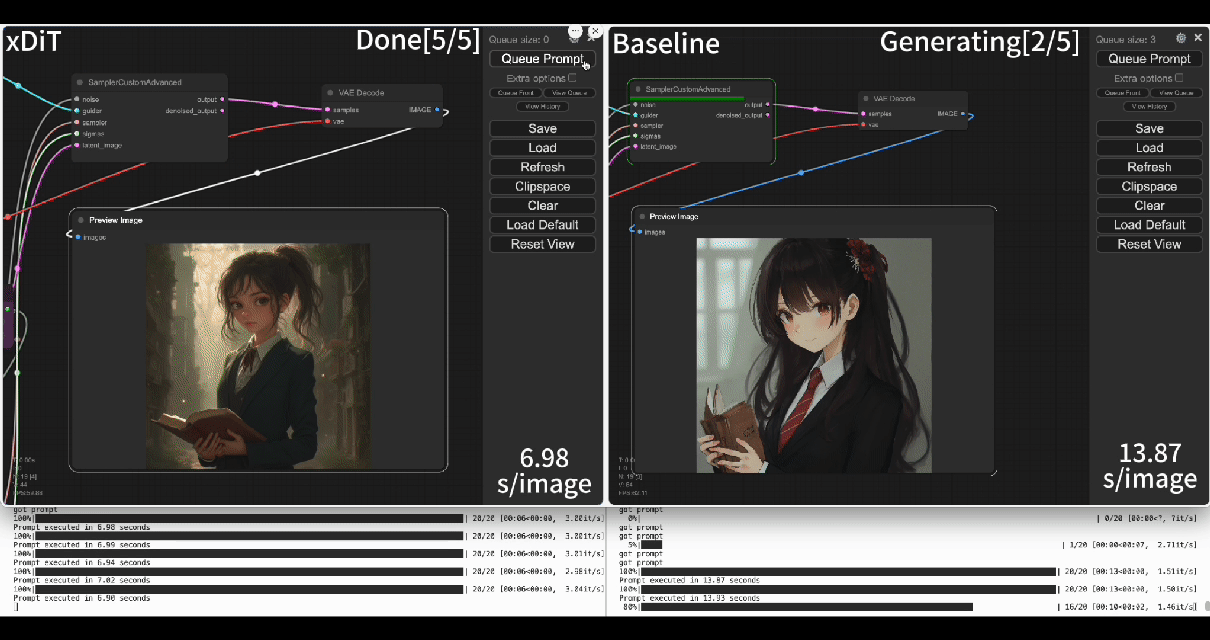
By using TACO-DiT, you could significantly reduce your ComfyUI workflow inference latency, and boosting the throughput with Multi-GPUs. Now it is compatible with multiple Plug-ins, including ControlNet and LoRAs.
More features and details can be found in our Intro Video:
- [YouTube] TACO-DiT: Accelerating Your ComfyUI Generation Experience
- [Bilibili] TACO-DiT: 加速你的ComfyUI生成体验
The blog article is also available: [Supe
