Bilive
极快的B站直播录制、自动切片、自动渲染弹幕以及字幕并投稿至B站,综合多种模态模型,兼容超低配置机器。Extremely fast live recording, automatic slicing, rendering, uploading and Integrating MLLMs. Compatible with low configurations machines.
Install / Use
/learn @timerring/BiliveREADME
Bilibili Intelligent Live-In Velocity Engine
7 x 24 小时无人监守录制、渲染弹幕、识别字幕、自动切片、自动上传、兼容超低配机器,启动项目,人人都是录播员。
:page_facing_up: English Documentation | :gear: Installation | :thinking: Reporting Issues | :speech_balloon: Chat
<div> <img src="assets/dmx.png" alt="DMXAPI.cn" width="450" height="300" />大模型API(<a href="https://www.dmxapi.cn/register?aff=vRzR" target="_blank">DMXAPI</a>) 行业领先的 api 聚合平台 详细介绍
<details open> <summary> DMX = 大模型拼音首字母 </summary> <ul> <li><a href="https://www.dmxapi.cn/register?aff=vRzR">DMXAPI.cn</a> 一个key用全球大模型</li> <li>GPT Claude Gemini 6.8折起</li> <li><a href="https://ssvip.DMXAPI.com">ssvip.DMXAPI.com</a> 提供生产级稳定服务</li> </ul> </details> </div>支持模型
<div> <img src="assets/openai.svg" alt="OpenAI whisper" width="60" height="60" /> <img src="assets/zhipu-color.svg" alt="Zhipu GLM-4V-PLUS" width="60" height="60" /> <img src="assets/gemini-brand-color.svg" alt="Google Gemini 1.5 Pro" width="60" height="60" /> <img src="assets/qwen-color.svg" alt="Qwen-2.5-72B-Instruct" width="60" height="60" /> <img src="assets/sensenova-brand-color.svg" alt="SenseNova V6 Pro" width="100" height="60" /> </div> <img src="assets/hunyuan-color.svg" alt="Tencent Hunyuan" width="50" height="60" /> <img src="assets/minimax-color.svg" alt="Minimax" width="20" height="60" /> <img src="assets/minimax-text.svg" alt="Minimax" width="60" height="60" /> <img src="assets/siliconcloud-color.svg" alt="SiliconFlow" width="15" height="60" /> <img src="assets/siliconcloud-text.svg" alt="SiliconFlow" width="100" height="60" /> <img src="assets/wenxin-color.svg" alt="Baidu ERNIE" width="60" height="60" /> <img src="assets/stability-brand-color.svg" alt="Stability AI" width="80" height="60" /> <img src="assets/luma-color.svg" alt="Luma Photon" width="20" height="60" /> <img src="assets/luma-text.svg" alt="Luma Photon" width="60" height="60" /> <img src="assets/ideogram.svg" alt="Ideogram V_2" width="50" height="60" /> <img src="assets/recraft.svg" alt="Recraft" width="50" height="60" /> <img src="assets/aws-color.svg" alt="Amazon" width="50" height="60" /> <img src="assets/hidream-color.svg" alt="Hidream I1" width="100" height="60" /> </div>1. Introduction
Have you noticed that Live-In is a wordplay :)
如果您觉得项目不错,欢迎 :star: 也欢迎 PR 合作,如果有任何疑问,欢迎提 issue 交流。
敬告:本项目仅供学习交流使用,请在征得对方许可的情况下录制,请勿未经授权私自将内容用于商业用途,请勿用于大规模录制,违者会被官方封禁,法律后果自负。
自动监听并录制B站直播和弹幕(含付费留言、礼物等),根据分辨率转换弹幕、语音识别字幕并渲染进视频,根据弹幕密度切分精彩片段并通过视频理解大模型生成有趣的标题,根据图像生成模型自动生成视频封面,自动投稿视频和切片至B站,兼容无GPU版本,兼容 x64 及 arm64 超低配置服务器与主机。
2. Major features
- 速度快:采用
pipeline流水线处理视频,理想情况下录播与直播相差半小时以内,没下播就能上线录播,已知 b 站录播最快的稳定版本! - ( 🎉 NEW)多架构:适配 amd64 及 arm64 架构!
- 多房间:同时录制多个直播间内容视频以及弹幕文件(包含普通弹幕,付费弹幕以及礼物上舰等信息)。
- 占用小:自动删除本地已上传的视频,极致节省空间。
- 模版化:无需复杂配置,开箱即用,通过 b 站搜索建议接口自动抓取相关热门标签。
- 检测片段并合并:对于网络问题或者直播连线导致的视频流分段,能够自动检测合并成为完整视频。
- 自动渲染弹幕:自动转换xml为ass弹幕文件,该转换工具库已经开源 DanmakuConvert 并且渲染到视频中形成有弹幕版视频并自动上传。
- 硬件要求极低:无需GPU,只需最基础的单核CPU搭配最低的运存即可完成录制,弹幕渲染,上传等等全部过程,无最低配置要求,10年前的电脑或服务器依然可以使用!
- ( :tada: NEW)自动渲染字幕:采用 OpenAI 的开源模型
whisper,自动识别视频内语音并转换为字幕渲染至视频中。 - ( :tada: NEW)自动切片上传:根据弹幕密度计算寻找高能片段并切片,该自动切片工具库已开源 auto-slice-video,结合多模态视频理解大模型自动生成有意思的切片标题及内容,并且自动上传,目前已经支持的模型有:
GLM-4V-PLUSGemini-2.5-flashQwen-2.5-72B-InstructSenseNova V6 Pro
- ( :tada: NEW)持久化登录/下载/上传视频(支持多p投稿):bilitool 已经开源,实现持久化登录,下载视频及弹幕(含多p)/上传视频(可分p投稿),查询投稿状态,查询详细信息等功能,一键pip安装,可以使用命令行 cli 操作,也可以作为api调用。
- ( :tada: NEW)自动多平台循环直播推流:该工具已经开源 looplive 是一个 7 x 24 小时全自动循环多平台同时推流直播工具。
- ( :tada: NEW)自动生成风格变换的视频封面:采用图生图多模态模型,自动获取视频截图并上传风格变换后的视频封面。
Minimax image-01Kwai KolorsTencent HunyuanBaidu ERNIE irag-1.0Stable Diffusion 3.5 large turboLuma PhotonIdeogram V_2RecraftAmazon Titan Image Generator V2Hidream I1kling-v1-5
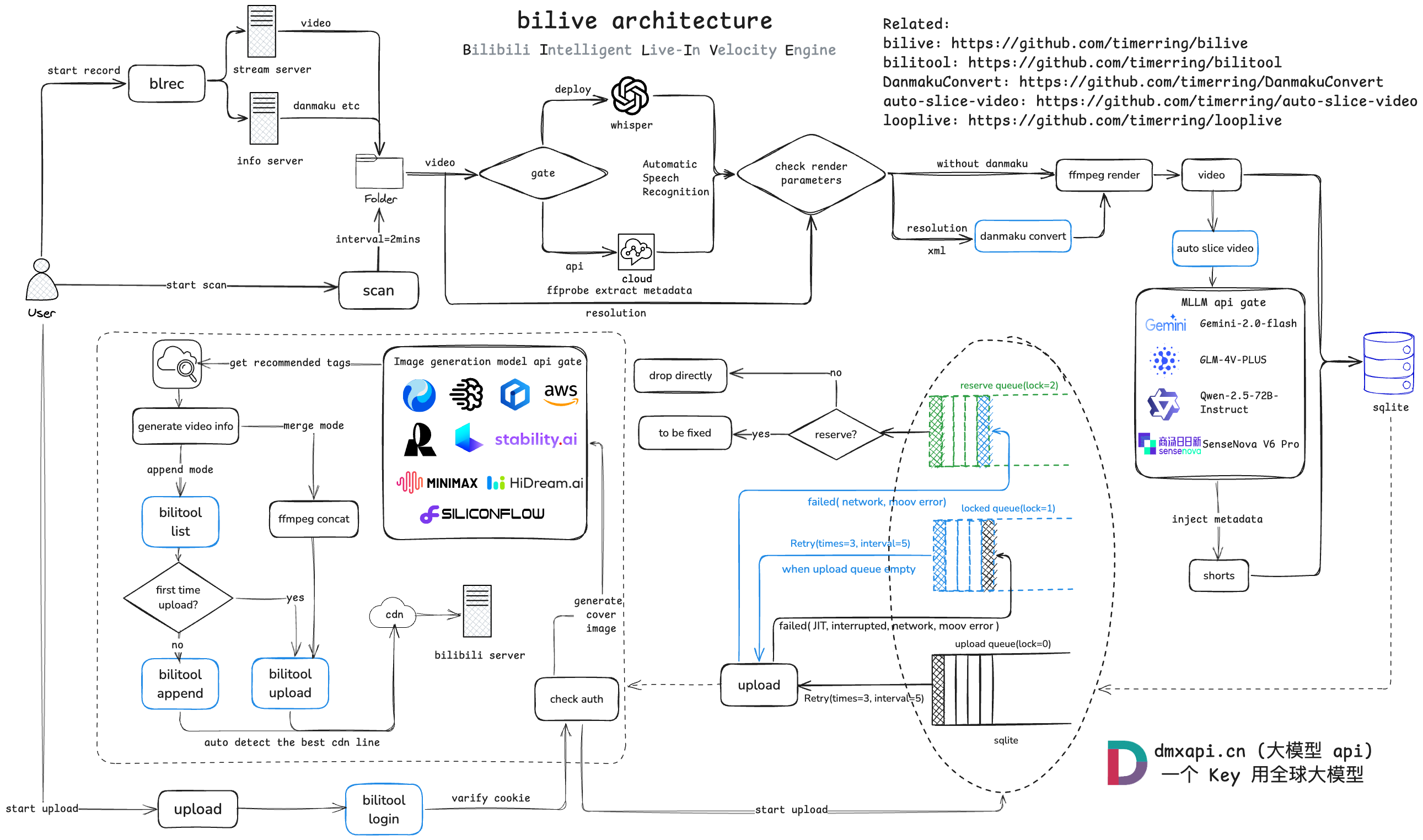
项目架构流程如下:
3. 测试硬件
| Machine | Alicloud | Oracle Cloud | local server | |--------|---------|---------|---------| | OS | Ubuntu 22.04.4 LTS | debian 6.1.0 | Ubuntu 22.04.4 LTS | | Architecture | x64 | aarch64 | x64 | | CPU | 2-core Intel(R) Xeon(R) Platinum 85 | 1-core Neoverse-N1 | 8-core Intel(R) Core(TM) i5-9300H CPU | | GPU | None | None | Nvidia GeForce GTX 1650 | | Memory | 2G | 4G | 24G | | Disk | 40G | 30G | 100G | | Bandwidth | 3Mbps | 100Mbps | 50Mbps | | Python Version | 3.10 | 3.10 | 3.10 |
个人经验:若想尽可能快地更新视频,主要取决于上传速度而非渲染速度,因此建议网络带宽越大越好。由于 aarch64 版本 PyPI 没有 release 的 triton 库,因此 aarch64 版本暂时不支持本地部署 whisper,pip 时请自行注释 requirement 中的 triton 环境,配置均测试可用。
4. Quick start
更详细的教程请参考文档 bilive
[!NOTE] 如果你是 windows 用户,请使用 WSL 运行本项目。
Mode
首先介绍本项目三种不同的处理模式:(以下特指 asr_method="deploy" 的情况,如填"none"或者"api"则不涉及 GPU, 可以忽略对 GPU 的描述)
pipeline模式(默认): 目前最快的模式,需要 GPU 支持,最好在blrec设置片段为半小时以内,asr 识别和渲染并行执行,分 p 上传视频片段。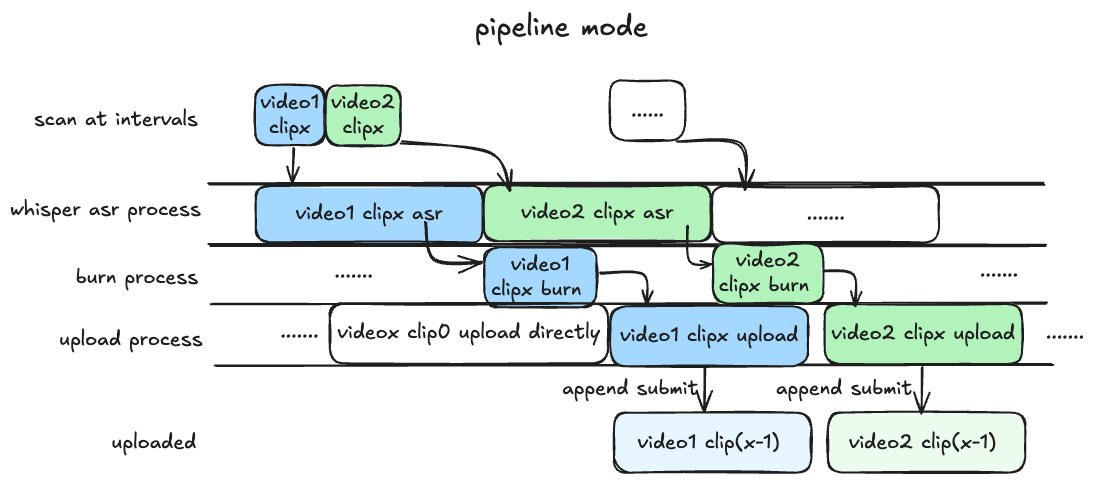
append模式: 基本同上,但 asr 识别与渲染过程串行执行,比 pipeline 慢预计 25% 左右,对 GPU 显存要求较低,兼顾硬件性能与处理上传效率。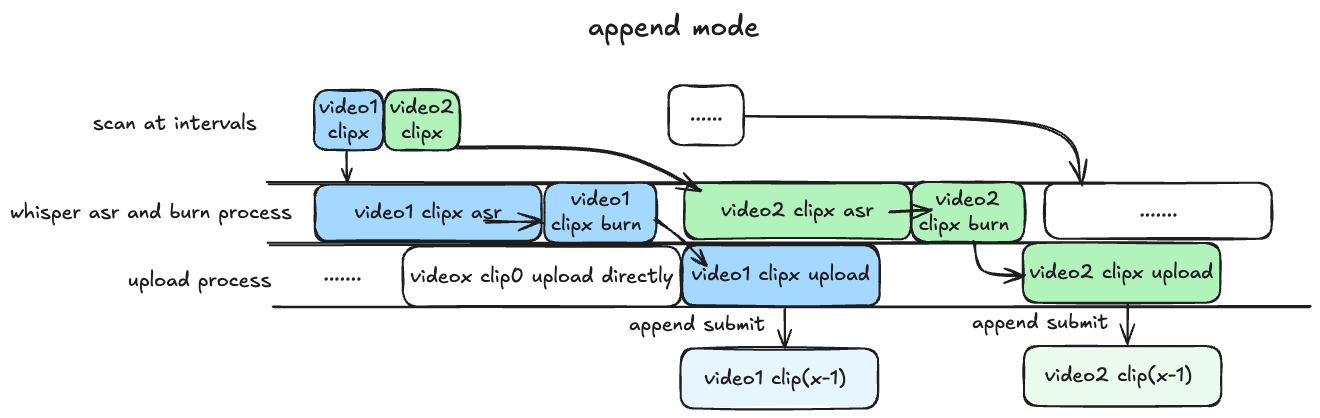
merge模式: 等待所有录制完成,再进行识别渲染合并过程,上传均为完整版录播(非分 P 投稿),等待时间较长,效率较慢,适合需要上传完整录播的场景。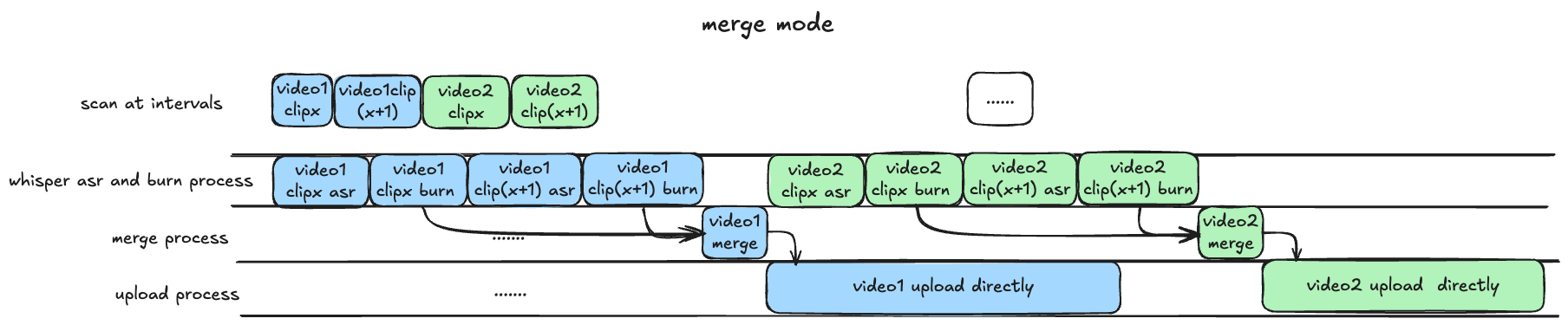
[!IMPORTANT] 凡是用到 GPU 均需保证 GPU 显存大于运行程序所需 VRAM,具体计算 VRAM 方法可以参考该部分。
Installation
[!TIP] 如果你是 windows 用户,请使用 WSL 运行本项目。
0. clone 项目
由于项目引入了我写的 submodule DanmakuConvert,bilitool 和 auto-slice-video,因此推荐 clone 项目时就更新 submodules。
git clone --recurse-submodules https://github.com/timerring/bilive.git
如果你没有采用上述方式 clone 项目,请更新 submodules:
git submodule update --init --recursive
1. 安装依赖(推荐创建虚拟环境)
cd bilive
pip install -r requirements.txt
此外请根据各自的系统类型安装对应的 ffmpeg,例如 ubuntu 安装 ffmpeg。
2. 配置参数
2.1 whisper 语音识别(渲染字幕功能)
[!TIP]
- 有关语音识别的配置在
bilive.toml文件的[asr]部分。asr_method默认为 none, 即不进行语音字幕识别。
2.1.1 采用 api 方式
将 bilive.toml 文件中的 asr_method 参数设置为 api,然后填写 WHISPER_API_KEY 参数为你的 API Key。
本项目采用 groq 提供 free tier 的 whisper-large-v3-turbo 模型,上传限制为 40 MB(约半小时),因此如需采用 api 识别的方式,请将视频录制分段调整为 30 分钟(默认即 30 分钟)。此外,free tier 请求限制为 7200秒/20次/小时,28800秒/2000次/天。如果有更多需求,也欢迎升级到 dev tier,更多信息见groq 官网。
2.1.2 采用本地部署方式(需保证有 NVIDIA 显卡)
将 bilive.toml 文件中的 asr_method 参数设置为 deploy,然后下载所需模型文件,并放置在 src/subtitle/models 文件夹中。
项目默认采用 small 模型,请点击下载所需文件,并放置在 src/subtitle/models 文件夹中。
[!TIP]
- 请保证 NVIDIA 显卡驱动安装正确
nvidia-sminvcc -V,并能够调用 CUDA 核心print(torch.cuda.is_available())返回True。如果未配置显卡驱动或未安装CUDA,即使有 GPU 也无法使用,而会使用 CPU 推理,非常消耗 CPU 计算资源,不推荐,如果 CPU 硬件条件好可以尝试。- 使用该参数模型至少需要保证有显存大于 2.7GB 的 GPU,否则请使用其他参数量的模型。
- 更多模型请参考 whisper 参数模型 部分。
- 更换模型方法请参考 更换模型方法 部分。
2.2 MLLM 模型(自动切片功能)
[!TIP]
- 有关自动切片的配置在
bilive.toml文件的[slice]部分。auto_slice默认为 false, 即不进行自动切片。- 可以通过单元测试调试你自己的 prompt,单元测试在
tests/test_autoslice.py,执行python -m unittest即可,后接tests.test_autoslice测试整个模块,tests.test_autoslice.TestXXXMain测试某个模型。部分模型会返回多个标题及 emoji,请在 prompt 中指出,仅返回一个标题的字符串即可,推荐先自行调试确保您的 prompt works,欢迎在 issue 中分享你的 prompt。
MLLM 模型主要用于自动切片后的切片标题生成,此功能默认关闭,如果需要打开请将 auto_slice 参数设置为 true,并且写下你自己的 slice_prompt(可以包含 {artist} 关键词会自动替换),其他配置分别有:
slice_duration以秒为单位设置切片时长(不建议超过 180 秒)。slice_num设置切片数量。slice_overlap设置切片重叠时长。切片采用滑动窗口法处理,细节内容请见 auto-slice-videoslice_step设置切片步长。min_video_size设置最小被切片视频大小,防止对一些连线或者网络波动原因造成的短片段再切片。
接下来配置模型有关的 mllm_model 参数即对应的 api-key,请自行根据链接注册账号并且申请对应 api key,填写在对应的参数中,请注意以下模型只有你在 mllm_model 参数中设置的那个模型会生效。
| Company | Alicloud | zhipu | Google | SenseNova |
|----------------|-----------------------|------------------|-------------------|-------------------|
| Name | Qwen-2.5-72B-Instruct | GLM-4V-PLUS | Gemini-2.0-flash | SenseNova V6 Pro |
| mllm_model | qwen | zhipu | gemini | sensenova |
| API key | qwen_api_key | zhipu_api_key | gemini_api_key | sensenova_api_key |
2.3 Image Generation Model(自动生成视频封面)
[!TIP]
- 有关自动生成视频封面的配置在
bilive.toml文件的[cover]部分。generate_cover默认为 false, 即不进行自

{kind=link}