Simulflow
A Clojure library for building real-time voice-enabled AI Agents. Simulflow handles the orchestration of speech recognition, audio processing, and AI service integration with the elegance of functional programming.
Install / Use
/learn @shipclojure/SimulflowREADME
Simulflow - Build realtime voice-enabled AI agents in a data centric way
<img src="./resources/simulflow.png" align="right" height="250" />Daydreaming is the first awakening of what we call simulflow. It is an essential tool of rational thought. With it you can clear the mind for better thinking. – Frank Herbert, Heretics of Dune
Bene Gesserit also have the ability to practice simulflow, literally the simultaneous flow of several threads of consciousness at any given time; mental multitasking, as it were. The combination of simulflow with their analytical abilities and Other Memory is responsible for the frightening intelligence of the average Bene Gesserit.
Simulflow, Dune Wiki

simulflow is a Clojure framework for building real-time voice-enabled AI applications using a data-driven, functional approach. Built on top of clojure.core.async.flow, it provides a composable pipeline architecture for processing audio, text, and AI interactions with built-in support for major AI providers.
[!WARNING] While Simulflow has been used in live, production applications - it's still under active development. Expect breaking changes to support new usecases
What is this?
Simulflow is a framework that uses processors that communicate through specialized frames to create voice-enabled AI agents. Think of it as a data pipeline where each component transforms typed messages:
Microphone Transport → (audio-in frames) → Transcriptor → (transcription frames) →
Context Aggregation → (context to LLM) → LLM → (streams response) →
Text Assembler → (sentence frames) → Text-to-Speech → (audio-out frames) →
Audio Splitter → (chunked audio) → Speaker Transport
This pipeline approach makes it easy to swap components, add new functionality, or debug individual stages without affecting the entire system.
Table of Contents
- Installation
- Requirements
- Video presentation
- Core Features
- Quick Start Example
- Examples
- Supported Providers
- Key Concepts
- Adding Custom Processes
- Built With
- Acknowledgements
- License
Installation
Clojure CLI/deps.edn
;; Add to your deps.edn
{:deps {com.shipclojure/simulflow {:mvn/version "0.1.8-alpha"}}}
Leiningen/Boot
;; Add to your project.clj
[com.shipclojure/simulflow "0.1.8-alpha"]
Maven
<dependency>
<groupId>com.shipclojure</groupId>
<artifactId>simulflow</artifactId>
<version>0.1.8-alpha</version>
</dependency>
Requirements
- Java 21+ - Required for virtual threads (Project Loom) support. If your java version doesn't support virtual threads,
simulflowdefaults to using normal threads. - Clojure 1.12+ - For core.async.flow and other modern Clojure features
Video presentation:
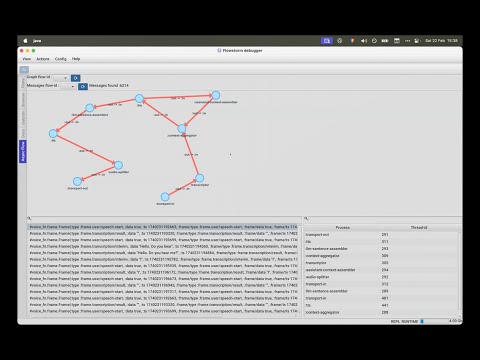
Core Features
- Flow-Based Architecture: Built on
core.async.flowfor robust concurrent processing - Data-First Design: Define AI pipelines as data structures for easy configuration and modification
- Streaming Architecture: Efficient real-time audio and text processing
- Extensible: Seamless to add new processors to embed into AI flows
- Flexible Frame System: Type-safe message passing between pipeline components
- Built-in Services: Ready-to-use integrations with major AI providers
Quick Start Example
First, create a resources/secrets.edn:
{:deepgram {:api-key ""}
:elevenlabs {:api-key ""
:voice-id ""}
:groq {:api-key ""}
:openai {:new-api-sk ""}}
Obtain the API keys from the respective providers and fill in the blank values.
Start a REPL and evaluate the snippets in the (comment ...) blocks to start the flows.
Allow Microphone access when prompted.
(ns simulflow-examples.local
{:clj-reload/no-unload true}
(:require
[clojure.core.async :as a]
[clojure.core.async.flow :as flow]
[simulflow.async :refer [vthread-loop]]
[simulflow.processors.activity-monitor :as activity-monitor]
[simulflow.processors.deepgram :as deepgram]
[simulflow.processors.elevenlabs :as xi]
[simulflow.processors.llm-context-aggregator :as context]
[simulflow.processors.openai :as openai]
[simulflow.secrets :refer [secret]]
[simulflow.transport :as transport]
[simulflow.transport.in :as transport-in]
[simulflow.transport.out :as transport-out]
[simulflow.utils.core :as u]
[simulflow.vad.silero :as silero]
[taoensso.telemere :as t]))
(defn make-local-flow
"This example showcases a voice AI agent for the local computer."
([] (make-local-flow {}))
([{:keys [llm-context extra-procs extra-conns debug? vad-analyser
language chunk-duration-ms]
:or {llm-context {:messages
[{:role "system"
:content "You are a voice agent operating via phone. Be
concise in your answers. The input you receive comes from a
speech-to-text (transcription) system that isn't always
efficient and may send unclear text. Ask for
clarification when you're unsure what the person said."}]}
language :en
debug? false
chunk-duration-ms 20
extra-procs {}
extra-conns []}}]
(flow/create-flow
{:procs
(u/deep-merge
{;; Capture audio from microphone and send raw-audio-input frames
:transport-in {:proc transport-in/microphone-transport-in
:args {:vad/analyser vad-analyser}}
;; raw-audio-input -> transcription frames
:transcriptor {:proc deepgram/deepgram-processor
:args {:transcription/api-key (secret [:deepgram :api-key])
:transcription/interim-results? true
:transcription/punctuate? false
:transcription/vad-events? false
:transcription/smart-format? true
:transcription/model :nova-2
:transcription/utterance-end-ms 1000
:transcription/language language}}
;; user transcription & llm message frames -> llm-context frames
:context-aggregator {:proc context/context-aggregator
:args {:llm/context llm-context
:aggregator/debug? debug?}}
;; Takes llm-context frames and produces llm-text-chunk & llm-tool-call-chunk frames
:llm {:proc openai/openai-llm-process
:args {:openai/api-key (secret [:openai :new-api-sk])
:llm/model "gpt-4o-mini"}}
;; llm-text-chunk & llm-tool-call-chunk -> llm-context-messages-append frames
:assistant-context-assembler {:proc context/assistant-context-assembler
:args {:debug? debug?}}
;; llm-text-chunk -> sentence speak frames (faster for text to speech)
:llm-sentence-assembler {:proc context/llm-sentence-assembler}
;; speak-frames -> audio-output-raw frames
:tts {:proc xi/elevenlabs-tts-process
:args {:elevenlabs/api-key (secret [:elevenlabs :api-key])
:elevenlabs/model-id "eleven_flash_v2_5"
:elevenlabs/voice-id (secret [:elevenlabs :voice-id])
:voice/stability 0.5
:voice/similarity-boost 0.8
:voice/use-speaker-boost? true
:pipeline/language language}}
;; audio-output-raw -> smaller audio-output-raw frames for realtime
:audio-splitter {:proc transport/audio-splitter
:args {:audio.out/duration-ms chunk-duration-ms}}
;; speakers out
:transport-out {:proc transport-out/realtime-speakers-out-processor
:args {:audio.out/sending-interval chunk-duration-ms
:audio.out/duration-ms chunk-duration-ms}}
:activity-monitor {:proc activity-monitor/process
:args {::activity-monitor/timeout-ms 5000}}}
extra-procs)
:conns (concat
[[[:transport-in :out] [:transcriptor :in]]
[[:transcriptor :out] [:context-aggregator :in]]
[[:transport-in :sys-out] [:context-aggregator :sys-in]]
[[:context-aggregator :out] [:llm :in]]
;; Aggregate full context
[[:llm :out] [:assistant-context-assembler :in]]
[[:assistant-context-assembler :out] [:context-aggregator :in]]
;; Assemble sentence by sentence for fast speech
[[:llm :out] [:llm-sentence-assembler :in]]
[[:llm-sentence-assembler :out] [:tts :in]]
[[:tts :out] [:audio-splitter :in]]
[[:audio-splitter :out] [:transport-out :in]]
;; Activity detection
[[:transport-out :sys-out] [:activity-monitor :sys-in]]
[[:transport-in :sys-out] [:activity-monitor :sys-in]]
[[:transcriptor :sys-out] [:activity-monitor :sys-in]]
[[:activity-monitor :out] [:context-aggregator :in]]
[[:activity-monitor :out] [:tts :in]]]
extra-conns)})))
(comment
(def local-ai (make-local-flow {:vad-analyser (silero
