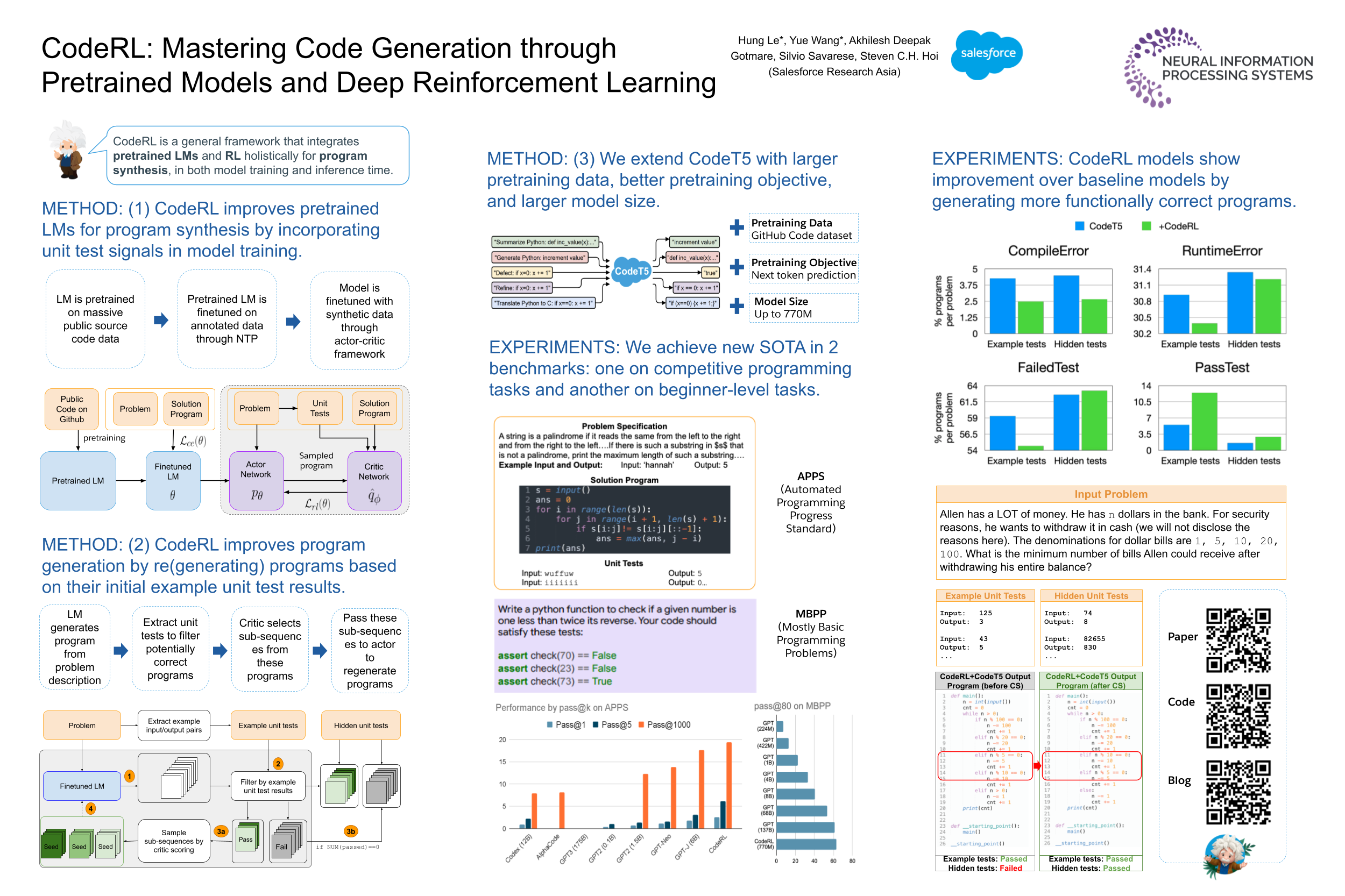
CodeRL
This is the official code for the paper CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning (NeurIPS22).
Install / Use
/learn @salesforce/CodeRLREADME
CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning <a name="corl"></a>
This is the official code for the paper CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning (accepted to NeurIPS 2022). Do check out our blog and poster.
Authors: Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, Steven C.H. Hoi
<p align="center"> <img src="images/ezgif-1-12f629284e.gif" width="100%" /> </p>Contents:
- [x] CodeRL Overview
- [x] Installation
- [x] Datasets
- [x] Models
- [x] CodeT5-large
- [x] CodeT5-large-ntp-py
- [x] CodeRL+CodeT5
- [x] Critic models
- [ ] Processes
- [x] Example Generated Programs
- [x] Citation
- [x] License
CodeRL Overview
<p align="center"> <img src="images/coderl_overview.png" width="100%" /> <br> <b>An example program synthesis task (Right)</b>: Each task includes a problem specification in natural language, which often contains example input and output pairs. The expected output is a program that is checked for functional correctness against some unit tests. <b>A high-level overview of our CodeRL framework for program synthesis (Left)</b>: Our CodeRL framework treats pretrained language model (LM) as a stochastic policy, token predictions as actions, and rewards can be estimated based on unit test results of output programs </p>- During training, we treat the code-generating language models as an actor network, and introduce a critic network that is trained to predict the functional correctness of generated programs and provide dense feedback signals to the actor.
- During inference, we introduce a new generation procedure with a critical sampling strategy that allows a model to automatically regenerate programs based on feedback from example unit tests and critic scores.
Installation
The code requires some dependencies as specified in requirements.txt. Please follow the relevant libraries to install or run:
pip install -r requirements.txt
Install the transformers library from the source code (the current source code is developed from the original code of version 4.16.1):
cd transformers
pip install -e .
Datasets
For pretraining, apart from the CodeSearchNet (CSN), we use the Python Github Code Dataset (GCPY). We have compiled public, non-personal data from GitHub consisting of permissively licensed Python code (e.g. “mit”, “apache-2”, “bsd-3-clause”, “bsd-2- 126 clause”, “cc0-1.0”, “unlicense”, “isc”). Please see the paper for more details on pretraining data preprocessing and pretraining.
After pretraining, we finetune/evaluate models on the following major program synthesis benchmarks:
- APPS: Please follow the downloading and preprocessing instructions provided here.
- MBPP: The dataset is available here.
On both benchmarks, we follow the same way of preprocessing data and constructing input/output sequences as the original benchmark papers.
Download and unzip all files into the data folder.
Example Unit Tests
In addition to the original hidden unit tests on APPS, we also utilize the example tests that are often embedded in problem descriptions.
After downloading and unzipping APPS, you can run the notebook extract_example_test.ipynb to extract and save example unit tests of APPS test samples into corresponding sample folder e.g. data/APPS/test/0000/.
We release the example unit tests that we already extracted using this notebook in the folder data/APPS_test_example_tests/. The average number of example unit tests per sample is 1.9764.
Models
We employ CodeT5 (a family of encoder-decoder language models for code from the paper) as the foundation model in our work.
We pretrained CodeT5 with bigger dataset and improved learning objectives. We release two large-sized CodeT5 checkpoints at Hugging Face: Salesforce/codet5-large and Salesforce/codet5-large-ntp-py.
- CodeT5-large: a 770M-CodeT5 model which was pretrained using Masked Span Prediction objective on CSN and achieved new SOTA results on several CodeXGLUE benchmarks. See Appendix A.1 of the paper for more details.
- CodeT5-large-ntp-py: A 770M-CodeT5 model which was first pretrained using Masked Span Prediction objective on CSN and GCPY, followed by using Next Token Prediction objective on GCPY. This checkpoint was especially optimized for Python code generation tasks and employed by CodeRL.
For finetuning on downstream code generation tasks on APPS, we adopted critic models for RL training. We released the following critic model checkpoints (on Google Cloud Storage):
- CodeT5-finetuned_critic: a CodeT5 model which is initialized from a normal CodeT5-base and trained as a classifier to predict unit test outcomes (one of Compile Error, Runtime Error, Failed Tests, and Passed Tests). The critic is used to estimate returns and facilitate RL finetuning.
- CodeT5-finetuned_critic_binary: similar to the prior model but was trained with binary annotations (Passed Tests or not Passed Tests only). This critic is used to facilitate generation procedures during inference.
We released the following finetuned code generation model checkpoints (on Google Cloud Storage):
- CodeT5-finetuned_CodeRL: a CodeT5 model which was initialized from the prior pretrained CodeT5-large-ntp-py and then finetuned on APPS following our CodeRL training framework.
Download all files into the models folder.
Processes
Generating Programs
We created scripts/generate.sh to generate programs on the APPS benchmark. You can directly run this file by configuring the following parameters:
| Parameters | Description | Example Values |
|:-----------------:|:--------------------------------------------------------------------------------------------------------:|:------------------------------:|
| model_path | Path to a trained CodeT5-style model | models/codet5_finetuned_codeRL |
| tokenizer_path | Path to the saved tokenizer for CodeT5 (or path to cache the tokenizer) | models/codet5_tokenizer/ |
| test_path | Path to the original test samples | data/APPS/test/ |
| start | start index of test samples to be generated | 0 |
| end | end index of test samples to be generated | 5000 |
|num_seqs | number of total output programs to be gen
Related Skills
proje
Interactive vocabulary learning platform with smart flashcards and spaced repetition for effective language acquisition.
YC-Killer
2.7kA library of enterprise-grade AI agents designed to democratize artificial intelligence and provide free, open-source alternatives to overvalued Y Combinator startups. If you are excited about democratizing AI access & AI agents, please star ⭐️ this repository and use the link in the readme to join our open source AI research team.
groundhog
398Groundhog's primary purpose is to teach people how Cursor and all these other coding agents work under the hood. If you understand how these coding assistants work from first principles, then you can drive these tools harder (or perhaps make your own!).
sec-edgar-agentkit
10AI agent toolkit for accessing and analyzing SEC EDGAR filing data. Build intelligent agents with LangChain, MCP-use, Gradio, Dify, and smolagents to analyze financial statements, insider trading, and company filings.

{kind=link}