VLMEvalKit
Open-source evaluation toolkit of large multi-modality models (LMMs), support 220+ LMMs, 80+ benchmarks
Install / Use
/learn @open-compass/VLMEvalKitQuality Score
Category
Customer SupportSupported Platforms
README
<b>A Toolkit for Evaluating Large Vision-Language Models. </b>
[![][github-contributors-shield]][github-contributors-link] • [![][github-forks-shield]][github-forks-link] • [![][github-stars-shield]][github-stars-link] • [![][github-issues-shield]][github-issues-link] • [![][github-license-shield]][github-license-link]
<a href="https://rank.opencompass.org.cn/leaderboard-multimodal">🏆 OC Learderboard </a> • <a href="#%EF%B8%8F-quickstart">🏗️Quickstart </a> • <a href="#-datasets-models-and-evaluation-results">📊Datasets & Models </a> • <a href="#%EF%B8%8F-development-guide">🛠️Development </a>
<a href="https://huggingface.co/spaces/opencompass/open_vlm_leaderboard">🤗 HF Leaderboard</a> • <a href="https://huggingface.co/datasets/VLMEval/OpenVLMRecords">🤗 Evaluation Records</a> • <a href="https://huggingface.co/spaces/opencompass/openvlm_video_leaderboard">🤗 HF Video Leaderboard</a> •
<a href="https://discord.gg/evDT4GZmxN">🔊 Discord</a> • <a href="https://www.arxiv.org/abs/2407.11691">📝 Report</a> • <a href="#-the-goal-of-vlmevalkit">🎯Goal </a> • <a href="#%EF%B8%8F-citation">🖊️Citation </a>
</div>VLMEvalKit (the python package name is vlmeval) is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.
Recent Codebase Changes
-
[2025-09-12] Major Update: Improved Handling for Models with Thinking Mode
A new feature in PR 1229 that improves support for models with thinking mode. VLMEvalKit now allows for the use of a custom
split_thinkingfunction. We strongly recommend this for models with thinking mode to ensure the accuracy of evaluation. To use this new functionality, please enable the Environment Variable:SPLIT_THINK=True. By default, the function will parse content within<think>...</think>tags and store it in thethinkingkey of the output. For more advanced customization, you can also create asplit_thinkfunction for model. Please see the InternVL implementation for an example. -
[2025-09-12] Major Update: Improved Handling for Long Response(More than 16k/32k)
A new feature in PR 1229 that improves support for models with long response outputs. VLMEvalKit can now save prediction files in TSV format. Since individual cells in an
.xlsxfile are limited to 32,767 characters, we strongly recommend using this feature for models that generate long responses (e.g., exceeding 16k or 32k tokens) to prevent data truncation. To use this new functionality, please enable the Environment Variable:PRED_FORMAT=tsv. -
[2025-08-04] In PR 1175, we refine the
can_infer_optionandcan_infer_text, which increasingly route the evaluation to LLM choice extractors and empirically leads to slight performance improvement for MCQ benchmarks.
🆕 News
- [2025-07-07] Supported SeePhys, which is a full spectrum multimodal benchmark for evaluating physics reasoning across different knowledge levels. thanks to Quinn777 🔥🔥🔥
- [2025-07-02] Supported OvisU1, thanks to liyang-7 🔥🔥🔥
- [2025-06-16] Supported PhyX, a benchmark aiming to assess capacity for physics-grounded reasoning in visual scenarios. 🔥🔥🔥
- [2025-05-24] To facilitate faster evaluations for large-scale or thinking models, VLMEvalKit supports multi-node distributed inference using LMDeploy (supports InternVL Series, QwenVL Series, LLaMa4) or VLLM(supports QwenVL Series, LLaMa4). You can activate this feature by adding the
use_lmdeployoruse_vllmflag to your custom model configuration in config.py . Leverage these tools to significantly speed up your evaluation workflows 🔥🔥🔥 - [2025-05-24] Supported Models: InternVL3 Series, Gemini-2.5-Pro, Kimi-VL, LLaMA4, NVILA, Qwen2.5-Omni, Phi4, SmolVLM2, Grok, SAIL-VL-1.5, WeThink-Qwen2.5VL-7B, Bailingmm, VLM-R1, Taichu-VLR. Supported Benchmarks: HLE-Bench, MMVP, MM-AlignBench, Creation-MMBench, MM-IFEval, OmniDocBench, OCR-Reasoning, EMMA, ChaXiv,MedXpertQA, Physics, MSEarthMCQ, MicroBench, MMSci, VGRP-Bench, wildDoc, TDBench, VisuLogic, CVBench, LEGO-Puzzles, Video-MMLU, QBench-Video, MME-CoT, VLM2Bench, VMCBench, MOAT, Spatial457 Benchmark. Please refer to VLMEvalKit Features for more details. Thanks to all contributors 🔥🔥🔥
- [2025-02-20] Supported Models: InternVL2.5 Series, Qwen2.5VL Series, QVQ-72B, Doubao-VL, Janus-Pro-7B, MiniCPM-o-2.6, InternVL2-MPO, LLaVA-CoT, Hunyuan-Standard-Vision, Ovis2, Valley, SAIL-VL, Ross, Long-VITA, EMU3, SmolVLM. Supported Benchmarks: MMMU-Pro, WeMath, 3DSRBench, LogicVista, VL-RewardBench, CC-OCR, CG-Bench, CMMMU, WorldSense. Thanks to all contributors 🔥🔥🔥
- [2024-12-11] Supported NaturalBench, a vision-centric VQA benchmark (NeurIPS'24) that challenges vision-language models with simple questions about natural imagery.
- [2024-12-02] Supported VisOnlyQA, a benchmark for evaluating the visual perception capabilities 🔥🔥🔥
- [2024-11-26] Supported Ovis1.6-Gemma2-27B, thanks to runninglsy 🔥🔥🔥
- [2024-11-25] Create a new flag
VLMEVALKIT_USE_MODELSCOPE. By setting this environment variable, you can download the video benchmarks supported from modelscope 🔥🔥🔥
🏗️ QuickStart
See [QuickStart | 快速开始] for a quick start guide.
📊 Datasets, Models, and Evaluation Results
Evaluation Results
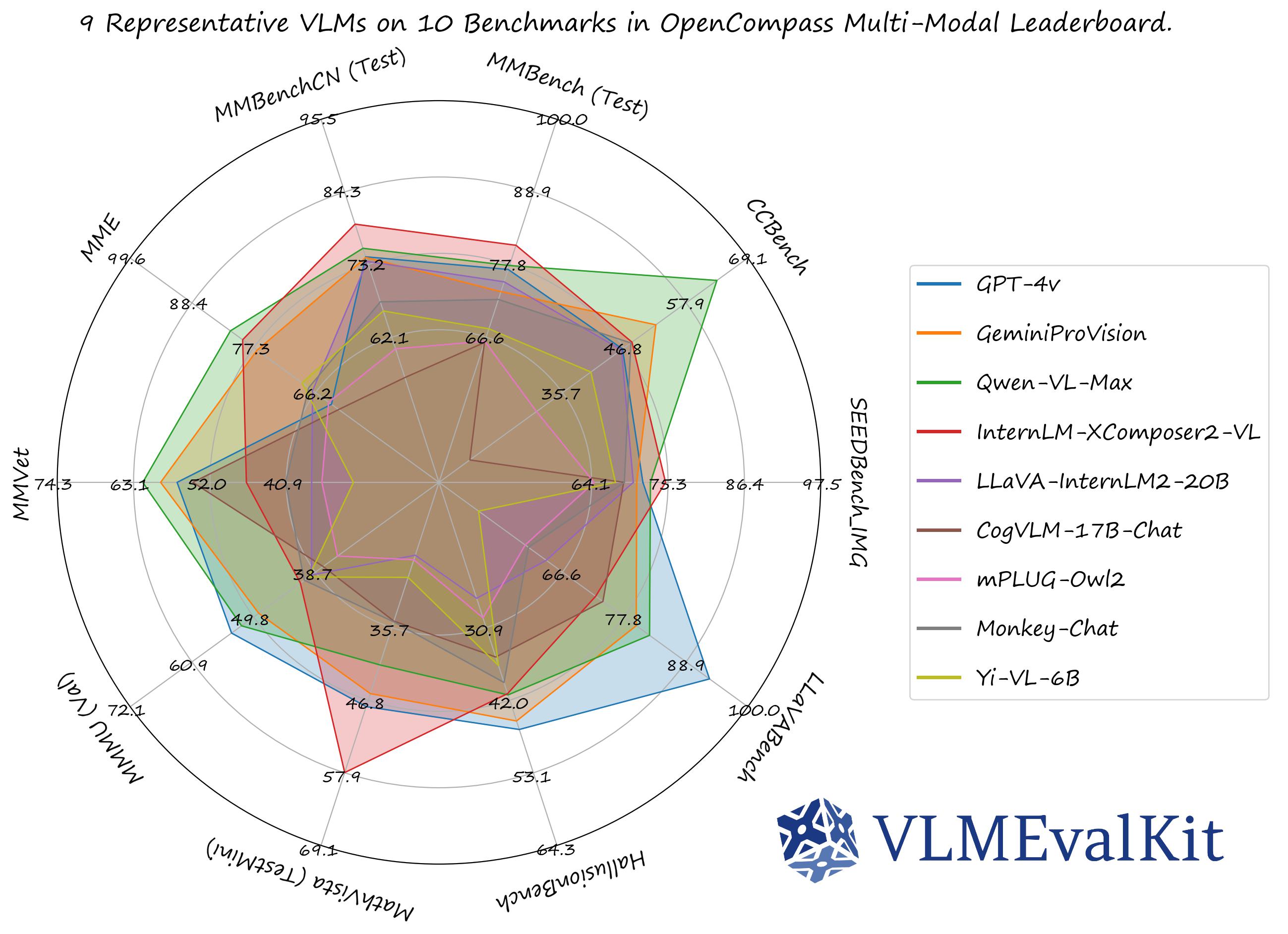
The performance numbers on our official multi-modal leaderboards can be downloaded from here!
OpenVLM Leaderboard: Download All DETAILED Results.
Check Supported Benchmarks Tab in VLMEvalKit Features to view all supported image & video benchmarks (70+).
Check Supported LMMs Tab in VLMEvalKit Features to view all supported LMMs, including commercial APIs, open-source models, and more (200+).
Transformers Version Recommendation:
Note that some VLMs may not be able to run under certain transformer versions, we recommend the following settings to evaluate each VLM:
- Please use
transformers==4.33.0for:Qwen series,Monkey series,InternLM-XComposer Series,mPLUG-Owl2,OpenFlamingo v2,IDEFICS series,VisualGLM,MMAlaya,ShareCaptioner,MiniGPT-4 series,InstructBLIP series,PandaGPT,VXVERSE. - Please use
transformers==4.36.2for:Moondream1. - Please use
transformers==4.37.0for:LLaVA series,ShareGPT4V series,TransCore-M,LLaVA (XTuner),CogVLM Series,EMU2 Series,Yi-VL Series,MiniCPM-[V1/V2],OmniLMM-12B,DeepSeek-VL series,InternVL series,Cambrian Series,VILA Series,Llama-3-MixSenseV1_1,Parrot-7B,PLLaVA Series. - Please use
transformers==4.40.0for:IDEFICS2,Bunny-Llama3,MiniCPM-Llama3-V2.5,360VL-70B,Phi-3-Vision,WeMM. - Please use
transformers==4.42.0for:AKI. - Please use
transformers==4.44.0for:Moondream2,H2OVL series. - Please use
transformers==4.45.0for:Aria. - Please use
transformers==4.48.0(or4.46.0) for:LLaVA-Next series(e.g.,llava-hf/llava-v1.6-vicuna-7b-hf). - Please use
transformers==latestfor:PaliGemma-3B,Chameleon series,Video-LLaVA-7B-HF,Ovis series,Mantis series,MiniCPM-V2.6,OmChat-v2.0-13B-sinlge-beta,Idefics-3,GLM-4v-9B,VideoChat2-HD,RBDash_72b,Llama-3.2 series,Kosmos series. - Please use
transformers==4.50.3(or4.46.1or4.51or4.53) for:Molmo series. - Please use
transformers>=5.2.0for:Qwen3.5 series.
Torchvision Version Recommendation:
Note that some VLMs may not be able to run under certain torchvision versions, we recommend the following settings to evaluate each VLM:
- Please use
torchvision>=0.16for:Moondream seriesandAria
Flash-attn Version Recommendation:
Note that some VLMs may not be able to run under certain flash-attention versions, we recommend the following settings to evaluate each VLM:
- Please use
pip install flash-attn --no-build-isolationfor:Aria
# Demo
from vlmeval.config import supported_VLM
model = supported_VLM['idefics_9b_instruct']()
# Forward Single Image
ret = model.generate(['assets/apple.jpg', 'What is in this image?'])
print(ret) # The image features a red apple with a leaf on it.
# Forward Multiple Images
ret = model.generate(['assets/apple.jpg', 'assets/apple.jpg', 'How many apples are there in the provided images? '])
print(ret) # There are two apples in the provided images.
