Logparser
A tool for parsing Scrapy log files periodically and incrementally, extending the HTTP JSON API of Scrapyd.
Install / Use
/learn @my8100/LogparserREADME
LogParser: A tool for parsing Scrapy log files periodically and incrementally, designed for ScrapydWeb.



![]()
![]()

Installation
- Use pip:
pip install logparser
:heavy_exclamation_mark: Note that you may need to execute python -m pip install --upgrade pip first in order to get the latest version of logparser, or download the tar.gz file from https://pypi.org/project/logparser/#files and get it installed via pip install logparser-x.x.x.tar.gz
- Use git:
pip install --upgrade git+https://github.com/my8100/logparser.git
Or:
git clone https://github.com/my8100/logparser.git
cd logparser
python setup.py install
Usage
To use in Python
<details> <summary>View codes</summary>In [1]: from logparser import parse
In [2]: log = """2018-10-23 18:28:34 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: demo)
...: 2018-10-23 18:29:41 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
...: {'downloader/exception_count': 3,
...: 'downloader/exception_type_count/twisted.internet.error.TCPTimedOutError': 3,
...: 'downloader/request_bytes': 1336,
...: 'downloader/request_count': 7,
...: 'downloader/request_method_count/GET': 7,
...: 'downloader/response_bytes': 1669,
...: 'downloader/response_count': 4,
...: 'downloader/response_status_count/200': 2,
...: 'downloader/response_status_count/302': 1,
...: 'downloader/response_status_count/404': 1,
...: 'dupefilter/filtered': 1,
...: 'finish_reason': 'finished',
...: 'finish_time': datetime.datetime(2018, 10, 23, 10, 29, 41, 174719),
...: 'httperror/response_ignored_count': 1,
...: 'httperror/response_ignored_status_count/404': 1,
...: 'item_scraped_count': 2,
...: 'log_count/CRITICAL': 5,
...: 'log_count/DEBUG': 14,
...: 'log_count/ERROR': 5,
...: 'log_count/INFO': 75,
...: 'log_count/WARNING': 3,
...: 'offsite/domains': 1,
...: 'offsite/filtered': 1,
...: 'request_depth_max': 1,
...: 'response_received_count': 3,
...: 'retry/count': 2,
...: 'retry/max_reached': 1,
...: 'retry/reason_count/twisted.internet.error.TCPTimedOutError': 2,
...: 'scheduler/dequeued': 7,
...: 'scheduler/dequeued/memory': 7,
...: 'scheduler/enqueued': 7,
...: 'scheduler/enqueued/memory': 7,
...: 'start_time': datetime.datetime(2018, 10, 23, 10, 28, 35, 70938)}
...: 2018-10-23 18:29:42 [scrapy.core.engine] INFO: Spider closed (finished)"""
In [3]: odict = parse(log, headlines=1, taillines=1)
In [4]: odict
Out[4]:
OrderedDict([('head',
'2018-10-23 18:28:34 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: demo)'),
('tail',
'2018-10-23 18:29:42 [scrapy.core.engine] INFO: Spider closed (finished)'),
('first_log_time', '2018-10-23 18:28:34'),
('latest_log_time', '2018-10-23 18:29:42'),
('runtime', '0:01:08'),
('first_log_timestamp', 1540290514),
('latest_log_timestamp', 1540290582),
('datas', []),
('pages', 3),
('items', 2),
('latest_matches',
{'telnet_console': '',
'resuming_crawl': '',
'latest_offsite': '',
'latest_duplicate': '',
'latest_crawl': '',
'latest_scrape': '',
'latest_item': '',
'latest_stat': ''}),
('latest_crawl_timestamp', 0),
('latest_scrape_timestamp', 0),
('log_categories',
{'critical_logs': {'count': 5, 'details': []},
'error_logs': {'count': 5, 'details': []},
'warning_logs': {'count': 3, 'details': []},
'redirect_logs': {'count': 1, 'details': []},
'retry_logs': {'count': 2, 'details': []},
'ignore_logs': {'count': 1, 'details': []}}),
('shutdown_reason', 'N/A'),
('finish_reason', 'finished'),
('crawler_stats',
OrderedDict([('source', 'log'),
('last_update_time', '2018-10-23 18:29:41'),
('last_update_timestamp', 1540290581),
('downloader/exception_count', 3),
('downloader/exception_type_count/twisted.internet.error.TCPTimedOutError',
3),
('downloader/request_bytes', 1336),
('downloader/request_count', 7),
('downloader/request_method_count/GET', 7),
('downloader/response_bytes', 1669),
('downloader/response_count', 4),
('downloader/response_status_count/200', 2),
('downloader/response_status_count/302', 1),
('downloader/response_status_count/404', 1),
('dupefilter/filtered', 1),
('finish_reason', 'finished'),
('finish_time',
'datetime.datetime(2018, 10, 23, 10, 29, 41, 174719)'),
('httperror/response_ignored_count', 1),
('httperror/response_ignored_status_count/404', 1),
('item_scraped_count', 2),
('log_count/CRITICAL', 5),
('log_count/DEBUG', 14),
('log_count/ERROR', 5),
('log_count/INFO', 75),
('log_count/WARNING', 3),
('offsite/domains', 1),
('offsite/filtered', 1),
('request_depth_max', 1),
('response_received_count', 3),
('retry/count', 2),
('retry/max_reached', 1),
('retry/reason_count/twisted.internet.error.TCPTimedOutError',
2),
('scheduler/dequeued', 7),
('scheduler/dequeued/memory', 7),
('scheduler/enqueued', 7),
('scheduler/enqueued/memory', 7),
('start_time',
'datetime.datetime(2018, 10, 23, 10, 28, 35, 70938)')])),
('last_update_time', '2019-03-08 16:53:50'),
('last_update_timestamp', 1552035230),
('logparser_version', '0.8.1')])
In [5]: odict['runtime']
Out[5]: '0:01:08'
In [6]: odict['pages']
Out[6]: 3
In [7]: odict['items']
Out[7]: 2
In [8]: odict['finish_reason']
Out[8]: 'finished'
To run as a service
- Make sure that Scrapyd has been installed and started on the current host.
- Start LogParser via command
logparser - Visit http://127.0.0.1:6800/logs/stats.json (Assuming the Scrapyd service runs on port 6800.)
- Visit http://127.0.0.1:6800/logs/projectname/spidername/jobid.json to get stats of a job in details.
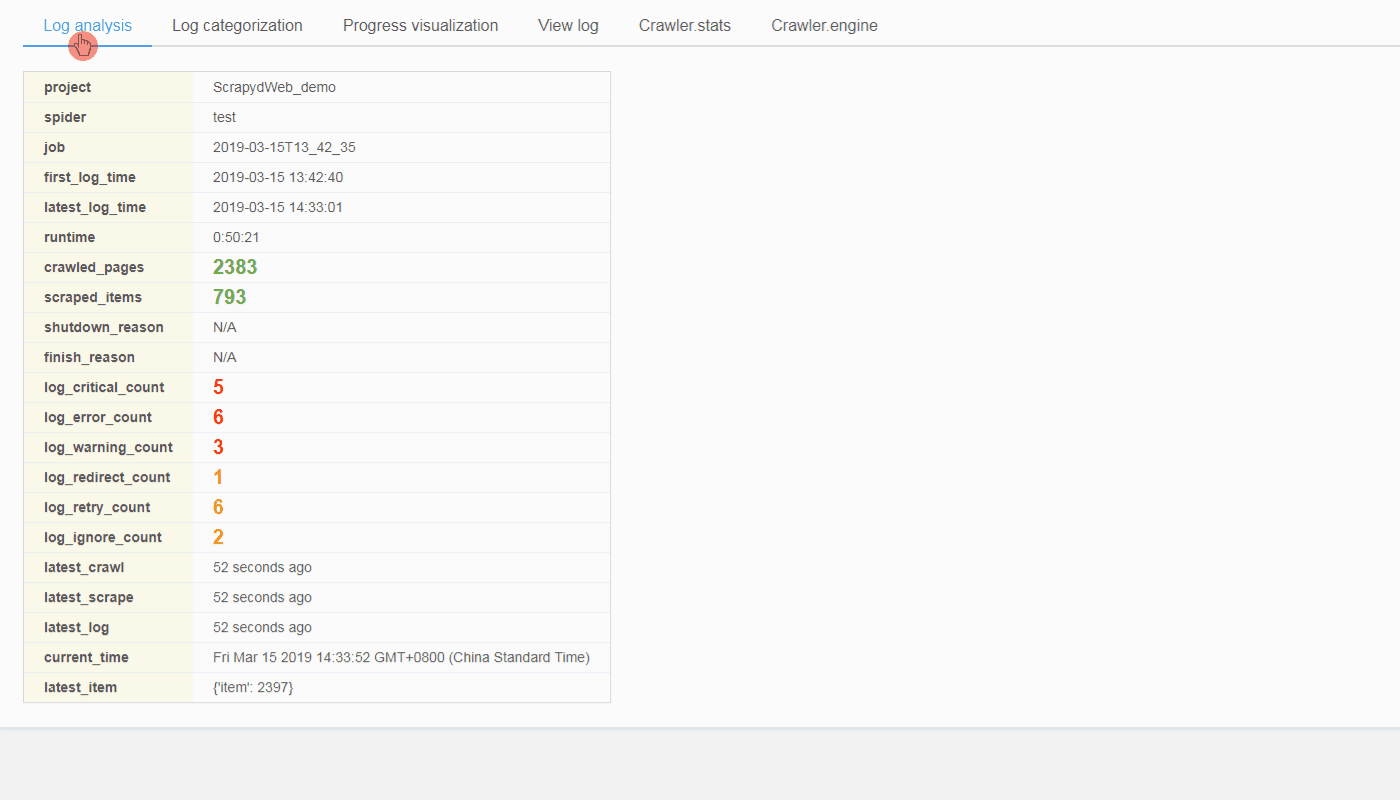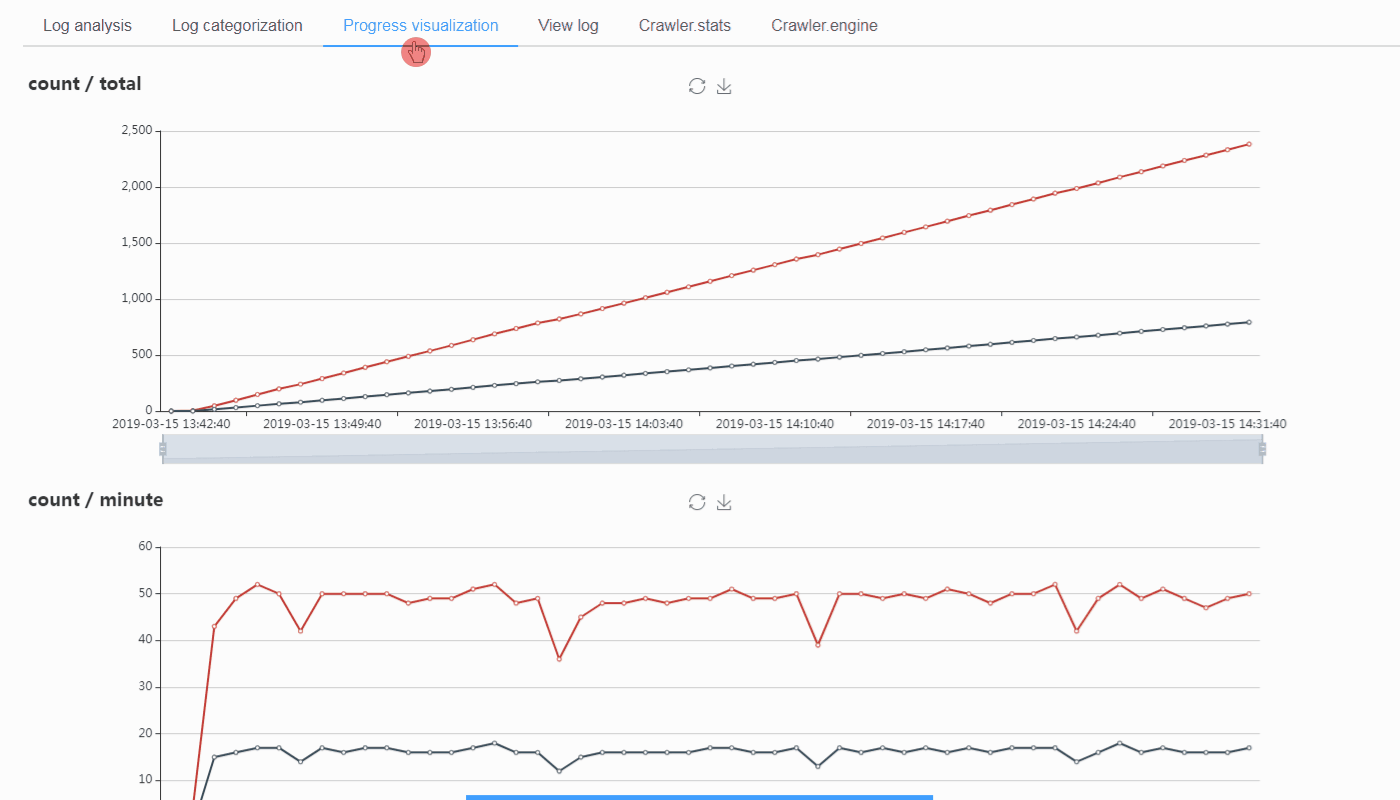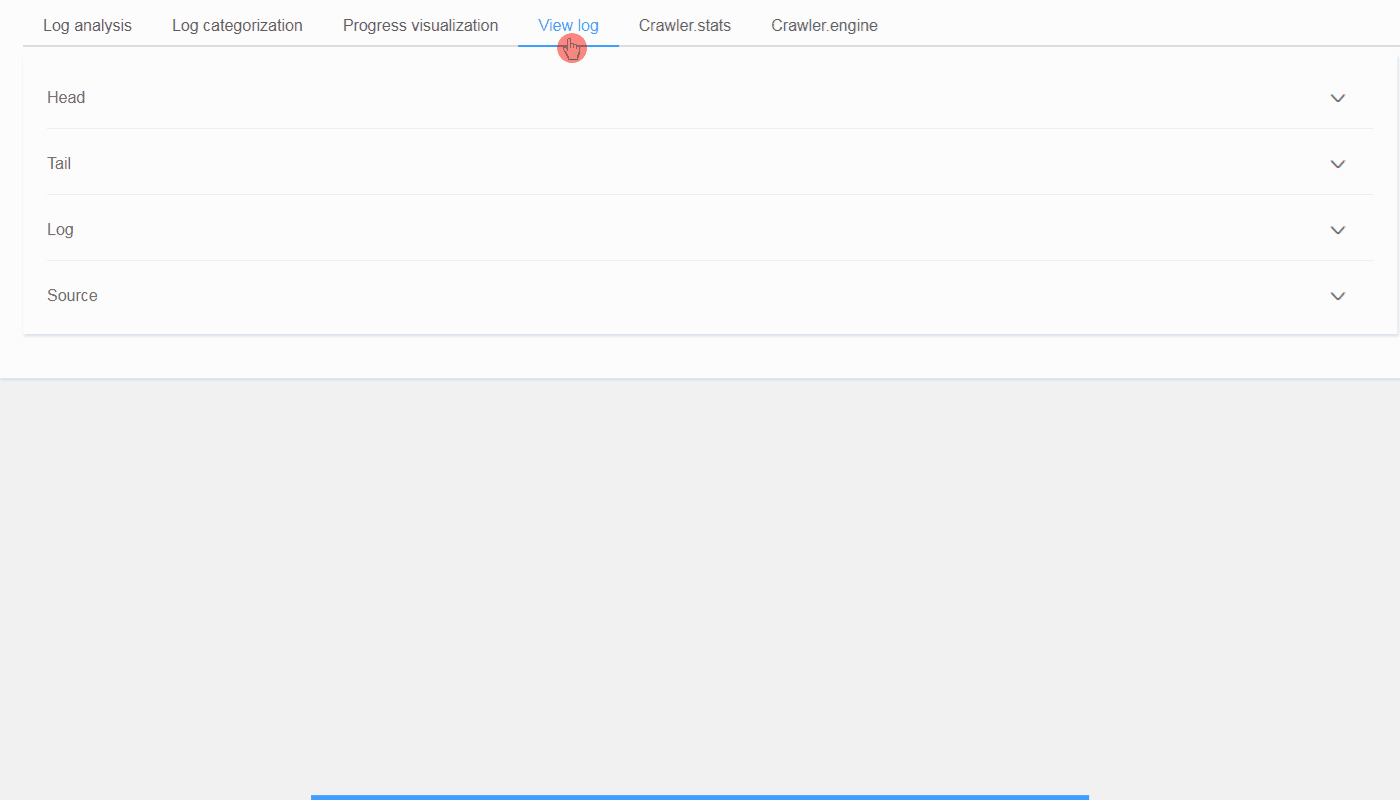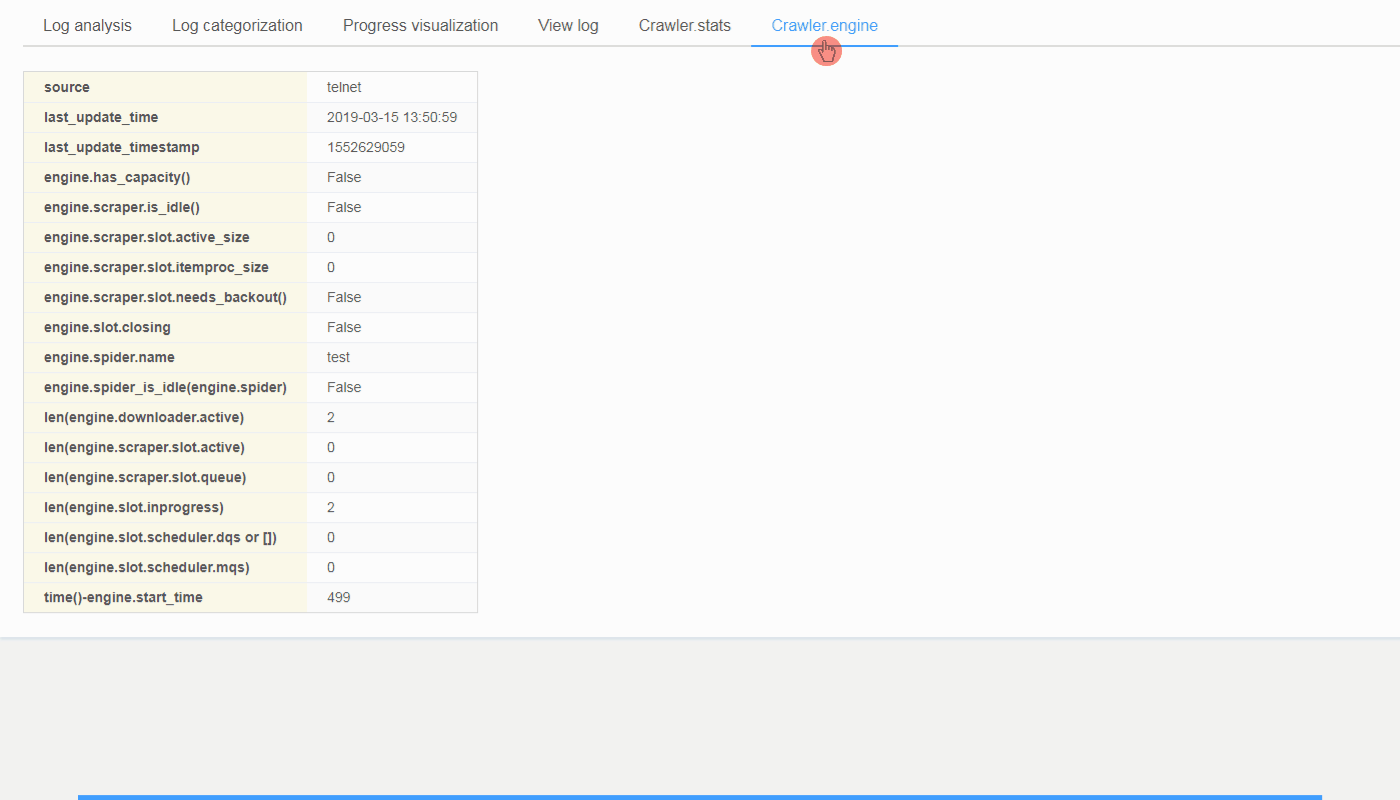
To work with ScrapydWeb for visualization
Check out https://github.com/my8100/scrapydweb for more info.
Related Skills
node-connect
339.5kDiagnose OpenClaw node connection and pairing failures for Android, iOS, and macOS companion apps
frontend-design
83.9kCreate distinctive, production-grade frontend interfaces with high design quality. Use this skill when the user asks to build web components, pages, or applications. Generates creative, polished code that avoids generic AI aesthetics.
openai-whisper-api
339.5kTranscribe audio via OpenAI Audio Transcriptions API (Whisper).
commit-push-pr
83.9kCommit, push, and open a PR
