MInference
[NeurIPS'24 Spotlight, ICLR'25, ICML'25] To speed up Long-context LLMs' inference, approximate and dynamic sparse calculate the attention, which reduces inference latency by up to 10x for pre-filling on an A100 while maintaining accuracy.
Install / Use
/learn @microsoft/MInferenceREADME
https://github.com/microsoft/MInference/assets/30883354/52613efc-738f-4081-8367-7123c81d6b19
Now, you can process 1M context 10x faster in a single A100 using Long-context LLMs like LLaMA-3-8B-1M, GLM-4-1M, with even better accuracy, try MInference 1.0 right now!
📰 News
- 🐝 [25/05/02] MMInference has been accepted at ICML'25.
- 👨💻 [25/04/14] SGLang and vLLM have merged the MInference sparse attention kernel. MInference already supports the optimized kernels. Just try
pip install sglang. You can achieve up to 1.64× (64K), 2.4× (96K), 2.9× (128K), 5.2× (256K), 8× (512K), and 15× (1M) speedup. Notably, SGLang also adapted it for FlashAttention-3. Special thanks to @zhyncs and @yinfan98 for their contributions! - 👾 [25/04/23] We are excited to announce the release of our multi-modality work, MMInference, which use modality-aware permutation sparse attention to accelerate long-context VLMs. We'll present MMInference at Microsoft Booth and FW-Wild at ICLR'25. See you in Singapore!
- 🤗 [25/01/27] MInference has been integrated into Qwen2.5-1M and online services. For details, refer to the paper and the vLLM implementation.
- 🪸 [25/01/23] SCBench has been accepted at ICLR'25.
TL;DR
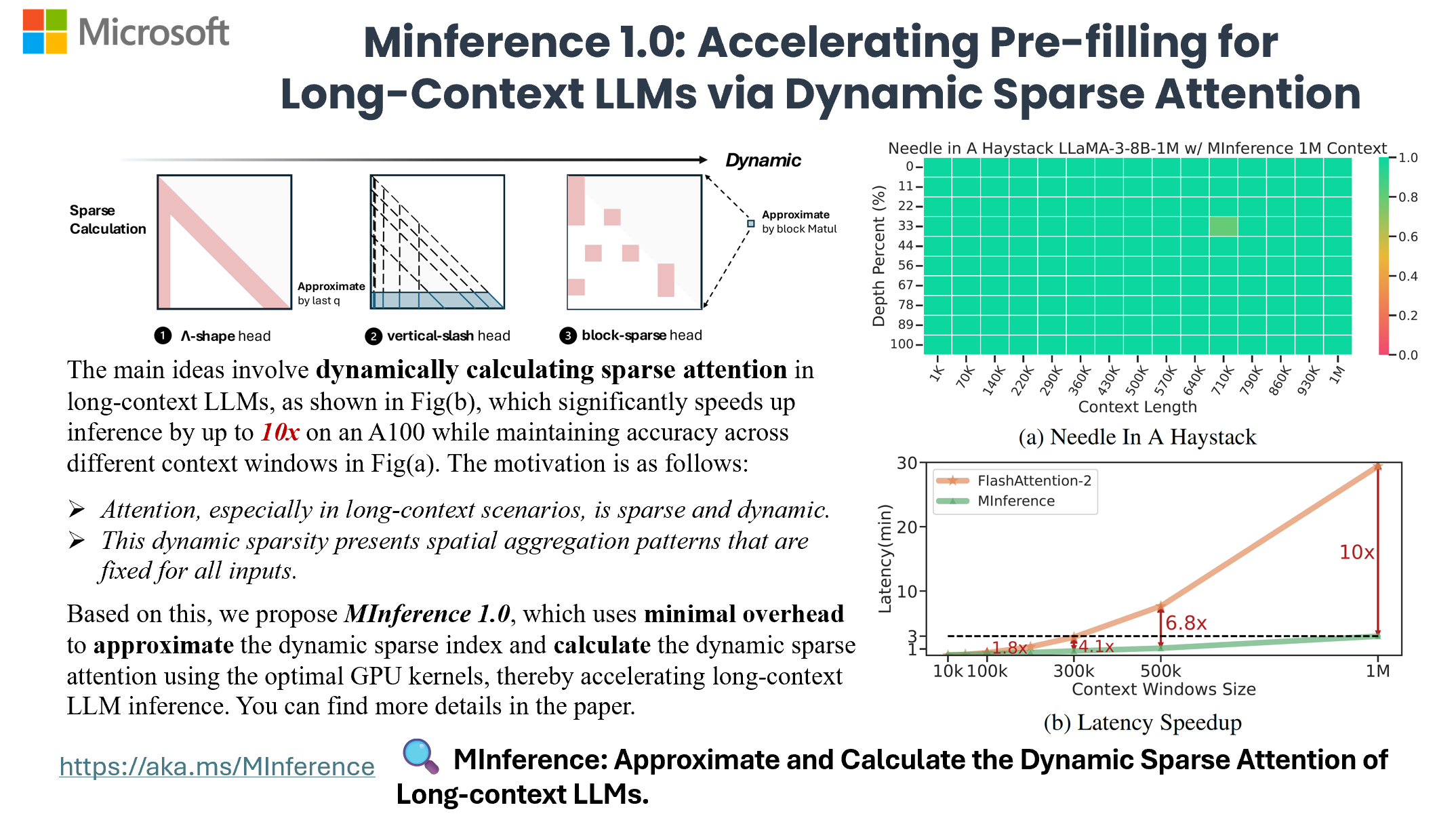
MInference 1.0 leverages the dynamic sparse nature of LLMs' attention, which exhibits some static patterns, to speed up the pre-filling for long-context LLMs. It first determines offline which sparse pattern each head belongs to, then approximates the sparse index online and dynamically computes attention with the optimal custom kernels. This approach achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy.
- MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention (NeurIPS'24 spotlight, ES-FoMo @ ICML'24)<br> Huiqiang Jiang†, Yucheng Li†, Chengruidong Zhang†, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang and Lili Qiu
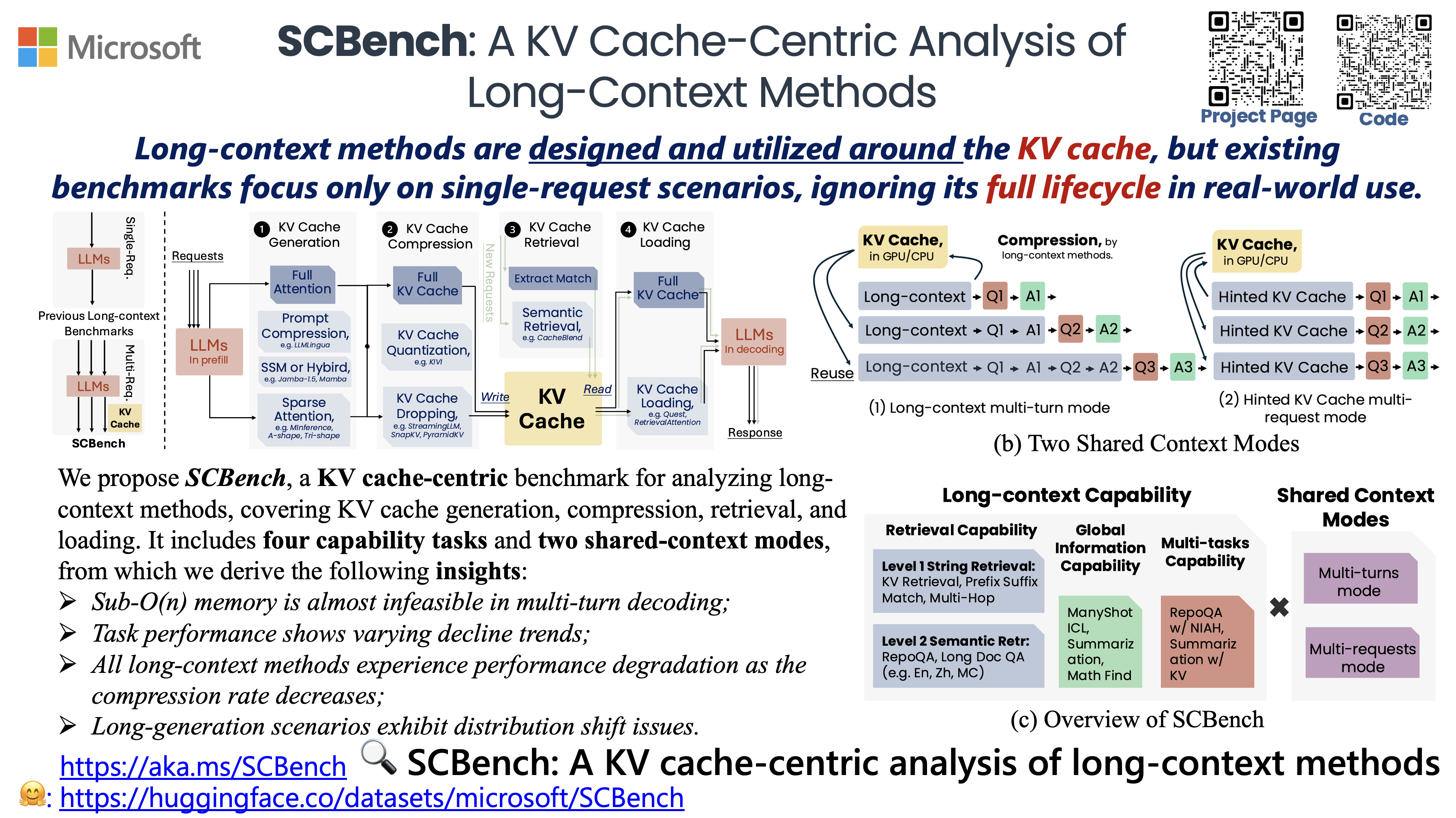
SCBench analyzes long-context methods from a KV cache-centric perspective across the full KV cache lifecycle (e.g., KV cache generation, compression, retrieval, and loading). It evaluates 12 tasks under two shared context modes, covering four categories of long-context capabilities: string retrieval, semantic retrieval, global information, and multi-task scenarios.
- SCBench: A KV Cache-Centric Analysis of Long-Context Methods (ICLR'25, ENLSP @ NeurIPS'24)<br> Yucheng Li, Huiqiang Jiang, Qianhui Wu, Xufang Luo, Surin Ahn, Chengruidong Zhang, Amir H. Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang and Lili Qiu
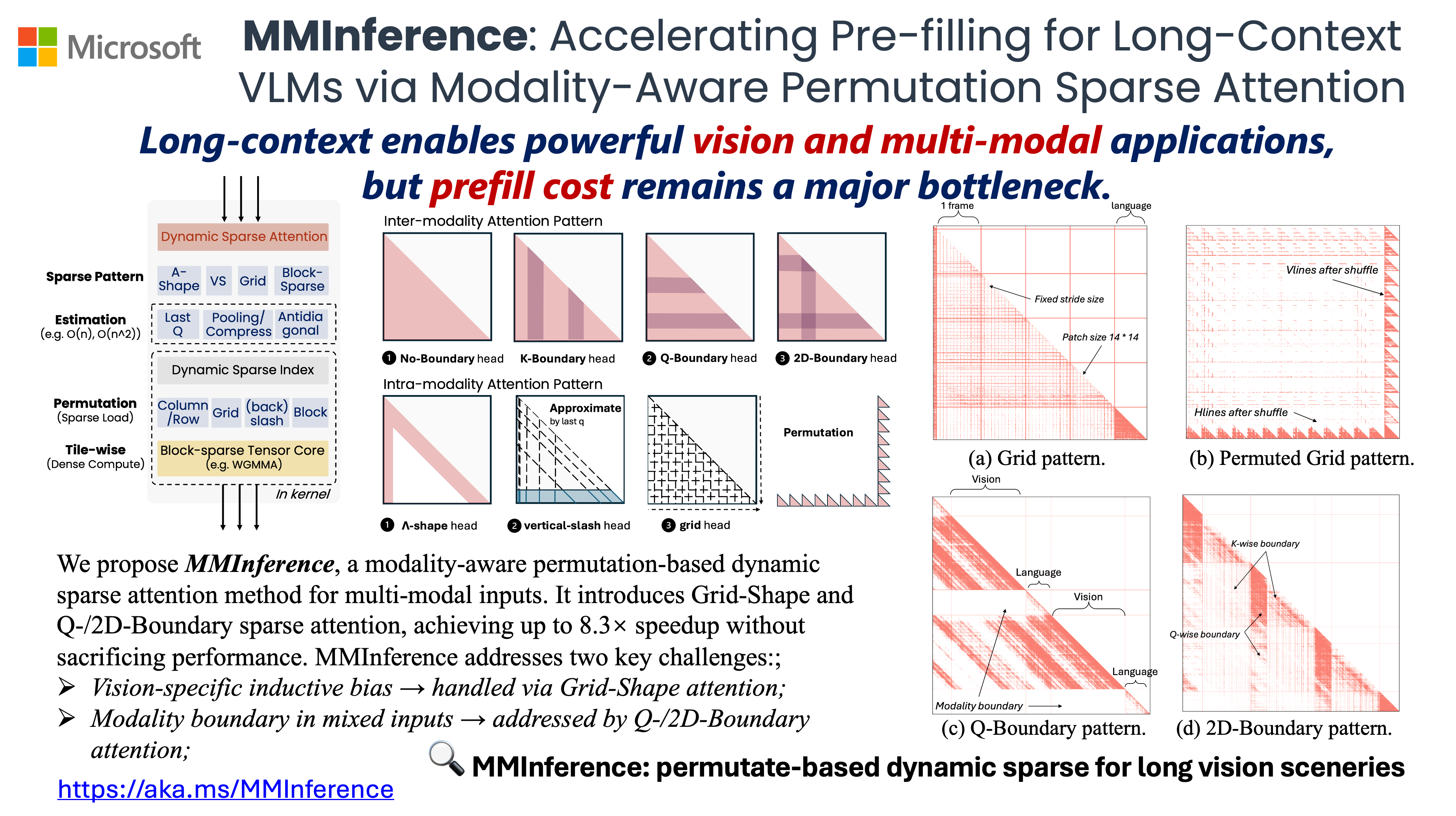
MMInference use modality-aware permutation sparse attention to accelerate long-context VLMs inference in prefilling-stage. Specifically, we implement three distinct permutation-based sparse attention mechanisms, with FlashAttention, FlashDecoding and PIT, to address the grid patterns in vision inputs and the modality boundary issues in mixed-modality scenarios.
- MMInference: Accelerating Pre-filling for Long-Context VLMs via Modality-Aware Permutation Sparse Attention (ICML'25, FM-Wild @ ICLR'25)<br> Yucheng Li, Huiqiang Jiang, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Amir H. Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang and Lili Qiu
🎥 Overview
🎯 Quick Start
Requirements
- Torch
- FlashAttention-2 (Optional)
- Triton
- Transformers >= 4.46.0
To get started with MInference, simply install it using pip:
pip install minference
Supported Efficient Methods
You can get the complete list of supported efficient methods by running the following code:
from minference import MInferenceConfig
supported_attn_types = MInferenceConfig.get_available_attn_types()
supported_kv_types = MInferenceConfig.get_available_kv_types()
Currently, we support the following long-context methods:
- [① KV Cache Generation]: MInference, xAttention, FlexPrefill, A-shape, Tri-shape, MInference w/ static, Dilated, Strided
- [② KV Cache Compression]: StreamingLLM, SnapKV, PyramidKV, KIVI
- [③ KV Cache Retrieval]: CacheBlend
- [④ KV Cache Loading]: Quest, RetrievalAttention
For more details about the KV cache lifecycle, please refer to SCBench. Note that some modes are supported by vLLM, while all modes are supported by HF.
Supported Models
General MInference supports any decoding LLMs, including LLaMA-style models, and Phi models. We have adapted nearly all open-source long-context LLMs available in the market. If your model is not on the supported list, feel free to let us know in the issues, or you can follow the guide to manually generate the sparse heads config.
You can get the complete list of supported LLMs by running:
from minference import get_support_models
get_support_models()
Currently, we support the following LLMs:
- Qwen2.5: Qwen/Qwen2.5-7B-Instruct, Qwen/Qwen2.5-32B-Instruct, Qwen/Qwen2.5-72B-Instruct, Qwen/Qwen2.5-7B-Instruct-1M, Qwen/Qwen2.5-14B-Instruct-1M
- LLaMA-3.1: meta-llama/Meta-Llama-3.1-8B-Instruct, meta-llama/Meta-Llama-3.1-70B-Instruct
- LLaMA-3: gradientai/Llama-3-8B-Instruct-262k, gradientai/Llama-3-8B-Instruct-Gradient-1048k, gradientai/Llama-3-8B-Instruct-Gradient-4194k, gradientai/Llama-3-70B-Instruct-Gradient-262k, gradientai/Llama-3-70B-Instruct-Gradient-1048k
- GLM-4: THUDM/glm-4-9b-chat-1m
- Yi: 01-ai/Yi-9B-200K
- Phi-3: microsoft/Phi-3-mini-128k-instruct
- Qwen2: Qwen/Qwen2-7B-Instruct
How to use MInference
[!TIP] To benefit from fast kernel implementations, we recommend installing SGLang or vLLM. for sglang
uv pip install "sglang[all]>=0.4.6.post4"for vll
