Myreader
基于React实现的【绿色版电子书阅读器】,可以免费看任何小说,支持离线下载,不过还是得支持正版哦!
Install / Use
/learn @liufulin90/MyreaderREADME
MyReader 绿色版电子书阅读器
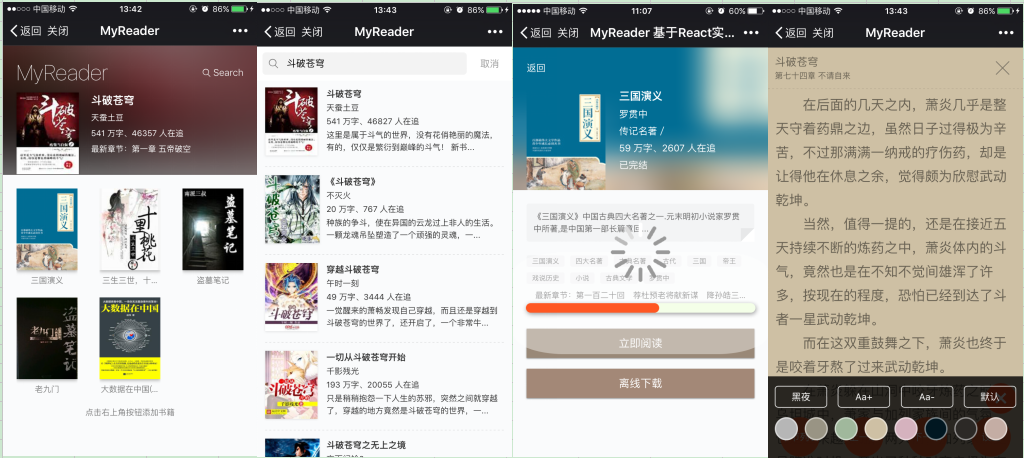
在线地址:http://myreader.linxins.com
手机扫码体验:

目录索引
store的设计与实现
effects 的逻辑处理
UI部分
优化
最后
开始
本项目没有使用任何脚手架工具和ui框架,因为本项目比较小,在时间允许的情况下,还是希望尽可能自己走一遍流程。
开发环境依然是react全家桶,基于最新版的webpack3、react15.6、react-router4、redux、redux-saga实现,就是不折腾不痛快。过程中略有小坑,比如热更新啦,dll动态链接库啦,preact不兼容啦,以及最新版本带来的不兼容什么的,不过都已经被社区大神趟平了。
store的设计与实现
首先来实现阅读器部分,关于电子阅读器我们可以总结出三个核心概念:书源、章节列表和章节内容。换源就是在书源中切换、跳转章节就是在章节列表中切换,我们只需要记录当前书源和当前章节就可以完整保存用户阅读进度。至于书籍详情当然也不能少,我们得知道当前到底看的是那一本书。
reader代表阅读器和当前书籍,这里我们跳过优质书源,原因大家都懂。 ╮( ̄▽ ̄)╭
阅读器
- src/store/reducer/reader.js
const initState = {
id: null, // 当前书籍id,默认没有书籍
currentSource: 1, // 当前源下标:默认为1,跳过优质书源
currentChapter: 0, // 当前章节下标
source: [], // 源列表
chapters: [], // 章节列表
chapter: {}, // 当前章节
detail: {}, // 书籍详情
menuState: false, // 底部菜单是否展开,默认不展开
};
function reader(state = initState, action) {
switch (action.type) {
case 'reader/save':
return {
...state,
...action.payload,
};
case 'reader/clear':
return initState;
default:
return {
...state,
};
}
}
export default reader;
书架
因为我们并不是要做只能阅读一本书的鸡肋,我们要的是能在多本书籍之间快速切换,不但能够保存阅读进度(当前书源和当前章节),并且可以在缓存中读取数据,过滤掉那些不必要的服务器请求。
为此,我们可以模仿现实中的书架来实现这个功能:前面提到的reader是当前正在阅读的书籍,它是完整的包含了一本书籍所有信息的个体,而书架则是很多个这样的个体的集合。因此切换书籍的动作,其实就是将书籍放回书架,再从书架中拿出一本书的过程,如果在书架中找到了这本书,便直接取出,进而得到上次阅读这本书的全部数据,如果没有找到这本书,就从服务器获取并初始化阅读器。
- src/store/reducer/store.js
function store(state = {}, action) {
switch (action.type) {
case 'store/put': { // 将书籍放入书架
if (action.key) {
return {
...state,
[action.key]: {
...state[action.key],
...action.payload,
},
};
} else {
return {
...state,
};
}
}
case 'store/save': // 初始化书架
return {
...state,
...action.payload,
};
case 'store/delete': // 删除书籍
return {
...state,
[action.key]: undefined,
};
case 'store/clear': // 清空书架
return {};
default:
return {
...state,
};
}
}
export default store;
effects 的逻辑处理
获取书源,可以说是项目中最核心的功能了。其实这个方法叫换源有些欠妥,应该叫做换书。主要功能就是实现了上文提到的将当前阅读书籍放回书架,并取出新书这个功能。并且这个方法只有在阅读一本新书时才会调用。
要考虑的情况基本就是用户第一次打开应用,没有当前阅读书籍,此时直接获取书源进行下一步下一步即可。当用户已经在看一本书,并且切换到同一本书时,直接返回,如果切换到另一本书,则将当前数据连同书籍信息一起打包放回书架,当然在此之前要先查看书架中有无这本书,有则取出,无则继续获取书源。需要注意的是,这里不要使用数组,而是将书籍id作为键值存在书架中,这会使得获取和查找都十分方便。
需要注意的一点是,项目本质上是web应用,用户可能从url进入任意页面,所以要做好异常情况的处理,例如没有书籍详情等。
获取书源
- src/store/effects/reader.js
/**
* 获取书源
* @param query
*/
function* getSource({ query }) {
try {
const { id } = query;
// 这里获得整个缓存中的store,并对应上reader的store。其reader的store结构参考store/reducer/reader.js initState
const { reader: { id: currentId, detail: { title } } } = yield select();
if (currentId) {
if (id !== currentId) {
const { reader, store: { [id]: book } } = yield select();
console.log(`将《${title}》放回书架`);
yield put({ type: 'store/put', payload: { ...reader }, key: currentId });
yield put({ type: 'reader/clear' });
if (book && book.detail && book.source) {
console.log(`从书架取回《${book.detail.title}》`);
yield put({ type: 'reader/save', payload: { ...book } });
return;
}
} else {
return;
}
}
let { search: { detail } } = yield select();
yield put({ type: 'common/save', payload: { loading: true } });
if (!detail._id) {
console.log('详情不存在,前往获取');
detail = yield call(readerServices.getDetail, id);
}
const data = yield call(readerServices.getSource, id);
console.log(`从网络获取《${detail.title}》`);
yield put({ type: 'reader/save', payload: { source: data, id, detail } });
console.log(`阅读:${detail.title}`);
yield getChapterList();
} catch (error) {
console.log(error);
}
yield put({ type: 'common/save', payload: { loading: false } });
}
章节列表-章节内容
获取章节列表和章节内容比较简单,只需稍稍做些异常情况的处理即可。
- src/store/effects/reader.js
/**
* 章节列表
*/
function* getChapterList() {
try {
const { reader: { source, currentSource } } = yield select();
console.log('获取章节列表', currentSource, source.length, JSON.stringify(source));
if (currentSource >= source.length) {
console.log('走到这里说明所有书源都已经切换完了');
yield put({ type: 'reader/save', payload: { currentSource: 0 } });
yield getChapterList();
return;
}
const { _id, name = '未知来源' } = source[currentSource];
console.log(`书源: ${name}`);
const { chapters } = yield call(readerServices.getChapterList, _id);
yield put({ type: 'reader/save', payload: { chapters } });
yield getChapter();
} catch (error) {
console.log(error);
}
}
/**
* 获取章节内容
*/
function* getChapter() {
try {
const { reader: { chapters, currentChapter,
downloadStatus, chaptersContent } } = yield select();
if (downloadStatus) { // 已下载直接从本地获取
const chapter = chaptersContent[currentChapter || 0];
console.log(`章节: ${chapter.title}`);
yield put({ type: 'reader/save', payload: { chapter } });
window.scrollTo(0, 0);
} else {
const { link } = chapters[currentChapter || 0];
yield put({ type: 'common/save', payload: { loading: true } });
const { chapter } = yield call(readerServices.getChapter, link);
if (chapter) {
console.log(`章节: ${chapter.title}`);
yield put({ type: 'reader/save', payload: { chapter } });
window.scrollTo(0, 0);
} else {
console.log('章节获取失败');
yield getNextSource();
}
}
} catch (error) {
console.log(error);
}
yield put({ type: 'common/save', payload: { loading: false } });
}
换源实现
同是核心功能,这个必须有。换源其实非常简单,做一个智(sha)能(gua)换源吧(根据书源获取具体章节,如果获取不到就拿下一个书源再获取其具体章节,直到获取到正确的为止)。
换源其实就是操作标记书源的指针,这很容易,我们关心的是何时换源。经过测试,发现获取章节列表这一步几乎都没有问题,错误基本上是发生在获取具体章节这一步。因此,我们只要在章节列表中稍作判断即可实现自动换源。换源方法如下。
- src/store/effects/reader.js
/**
* 获取下一个书源。
* 在获取书源后无法获取 具体章节 便会获取下一个书源。直到所有书源换完为止
*/
function* getNextSource() {
try {
const { reader: { source, currentSource } } = yield select();
let nextSource = (currentSource || 1) + 1;
console.log(`开始第${nextSource}个书源`);
if (nextSource >= source.length) {
console.log('没有可用书源,切换回优质书源');
nextSource = 0;
}
console.log(`正在尝试切换到书源: ${source[nextSource] && source[nextSource].name}`);
yield put({ type: 'reader/save', payload: { currentSource: nextSource } });
yield getChapterList();
} catch (error) {
console.log(error);
}
}
效果如下,当1号书源出错后我们自动跳转到下一个书源,很方便有木有。
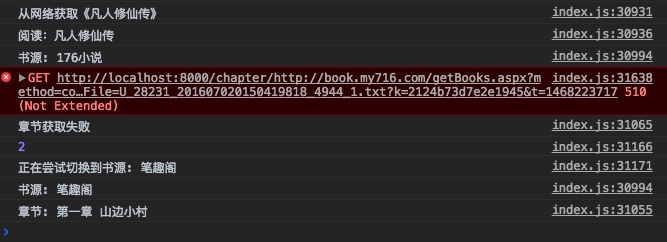
切换章节
非常简单,稍微做下异常处理就好。
- src/store/effects/reader.js
function* goToChapter({ payload }) {
try {
const { reader: { chapters } } = yield select();
const nextChapter = payload.nextChapter;
if (nextChapter > chapters.length) {
console.log('没有下一章啦');
return;
}
if (nextChapter < 0) {
console.log('没有上一章啦');
return;
}
yield put({ type: 'reader/save', payload: { currentChapter: nextChapter } });
yield getChapter();
} catch (error) {
console.log(error);
}
}
离线下载
考虑到节约流量问题,获取一个可用的书源后对每个章节去下载相应的章节内容,然后存储在本地(chaptersContent)。
- src/store/effects/reader.js
/**
* 离线下载书籍 获取书源
* @param query
*/
function* downGetSource({ query }) {
try {
const { id, download } = query;
// 这里获得整个缓存中的store,并对应上reader的store。其reader的store结构参考store/reducer/reader.js initState
// 同时获取该书是否下载的状态
const { reader: { id: currentId, detail: { title } } } = yield select();
console.log(`当前书信息currentId:${currentId} , id:${id}, title:${title}`);
if (download) {
const judgeRet = yield findBookByStoreId(id);
console.log('判断返回的结果:', judgeRet);
if (judgeRet.has && judgeRet.downloadStatus) {
console.log('已下载,直接阅读');
yield put({ type: 'reader/save', payload: { downloadStatus: true } });
return;
}
yield put({ type: 'common/save', payload: { loading: true } });
let { search: { detail } } = yield select();
if (!detail._id) {
console.log('下载时详情不存在,前往获取');
detail = yield call(readerServices.getDetail, id);
}
// 获得的所有书源
const sourceList = yield call(readerServices.getSource, id);
let sourceIndex = 0; // 标记书源当前脚标
let chapterList = []; // 初始化可用章节列表
// 循环获得一个可用的书源,达到自动换源的效果
for (let i = 0, len = sourceList.length; i < len; i += 1) {
if (sourceList[i].name !== '优质书源') {
const { chapters } = yield call(readerServices.getChapterList, sourceList[i]._id);
if (chapters.length) {
const { chapter, ok } = yield call(readerServices.getChapter, chapters[i].link);
if (ok && chapter) {
console.log(`成功获取一个书源 index: ${sourceIndex} 章节总数 ${chapters.length}`);
console.log('要下载的书源', sourceList[sourceIndex]);
// 成功获取一个书源,并将相关信息先存下来
yield put({ type: 'reader/save', payload: { source: sourceList, id, detail, chapters, chapter, downloadPercent: 0, currentSource: sourceIndex, currentChapter: 0 } });
chapterList = chapters;
br
