Langextract
A Python library for extracting structured information from unstructured text using LLMs with precise source grounding and interactive visualization.
Install / Use
/learn @google/LangextractREADME
LangExtract


![]()
![]()
Table of Contents
- Introduction
- Why LangExtract?
- Quick Start
- Installation
- API Key Setup for Cloud Models
- Adding Custom Model Providers
- Using OpenAI Models
- Using Local LLMs with Ollama
- More Examples
- Community Providers
- Contributing
- Testing
- Disclaimer
Introduction
LangExtract is a Python library that uses LLMs to extract structured information from unstructured text documents based on user-defined instructions. It processes materials such as clinical notes or reports, identifying and organizing key details while ensuring the extracted data corresponds to the source text.
Why LangExtract?
- Precise Source Grounding: Maps every extraction to its exact location in the source text, enabling visual highlighting for easy traceability and verification.
- Reliable Structured Outputs: Enforces a consistent output schema based on your few-shot examples, leveraging controlled generation in supported models like Gemini to guarantee robust, structured results.
- Optimized for Long Documents: Overcomes the "needle-in-a-haystack" challenge of large document extraction by using an optimized strategy of text chunking, parallel processing, and multiple passes for higher recall.
- Interactive Visualization: Instantly generates a self-contained, interactive HTML file to visualize and review thousands of extracted entities in their original context.
- Flexible LLM Support: Supports your preferred models, from cloud-based LLMs like the Google Gemini family to local open-source models via the built-in Ollama interface.
- Adaptable to Any Domain: Define extraction tasks for any domain using just a few examples. LangExtract adapts to your needs without requiring any model fine-tuning.
- Leverages LLM World Knowledge: Utilize precise prompt wording and few-shot examples to influence how the extraction task may utilize LLM knowledge. The accuracy of any inferred information and its adherence to the task specification are contingent upon the selected LLM, the complexity of the task, the clarity of the prompt instructions, and the nature of the prompt examples.
Quick Start
Note: Using cloud-hosted models like Gemini requires an API key. See the API Key Setup section for instructions on how to get and configure your key.
Extract structured information with just a few lines of code.
1. Define Your Extraction Task
First, create a prompt that clearly describes what you want to extract. Then, provide a high-quality example to guide the model.
import langextract as lx
import textwrap
# 1. Define the prompt and extraction rules
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")
# 2. Provide a high-quality example to guide the model
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"}
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"}
),
]
)
]
Note: Examples drive model behavior. Each
extraction_textshould ideally be verbatim from the example'stext(no paraphrasing), listed in order of appearance. LangExtract raisesPrompt alignmentwarnings by default if examples don't follow this pattern—resolve these for best results.
2. Run the Extraction
Provide your input text and the prompt materials to the lx.extract function.
# The input text to be processed
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
# Run the extraction
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
Model Selection:
gemini-2.5-flashis the recommended default, offering an excellent balance of speed, cost, and quality. For highly complex tasks requiring deeper reasoning,gemini-2.5-promay provide superior results. For large-scale or production use, a Tier 2 Gemini quota is suggested to increase throughput and avoid rate limits. See the rate-limit documentation for details.Model Lifecycle: Note that Gemini models have a lifecycle with defined retirement dates. Users should consult the official model version documentation to stay informed about the latest stable and legacy versions.
3. Visualize the Results
The extractions can be saved to a .jsonl file, a popular format for working with language model data. LangExtract can then generate an interactive HTML visualization from this file to review the entities in context.
# Save the results to a JSONL file
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".")
# Generate the visualization from the file
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:
if hasattr(html_content, 'data'):
f.write(html_content.data) # For Jupyter/Colab
else:
f.write(html_content)
This creates an animated and interactive HTML file:
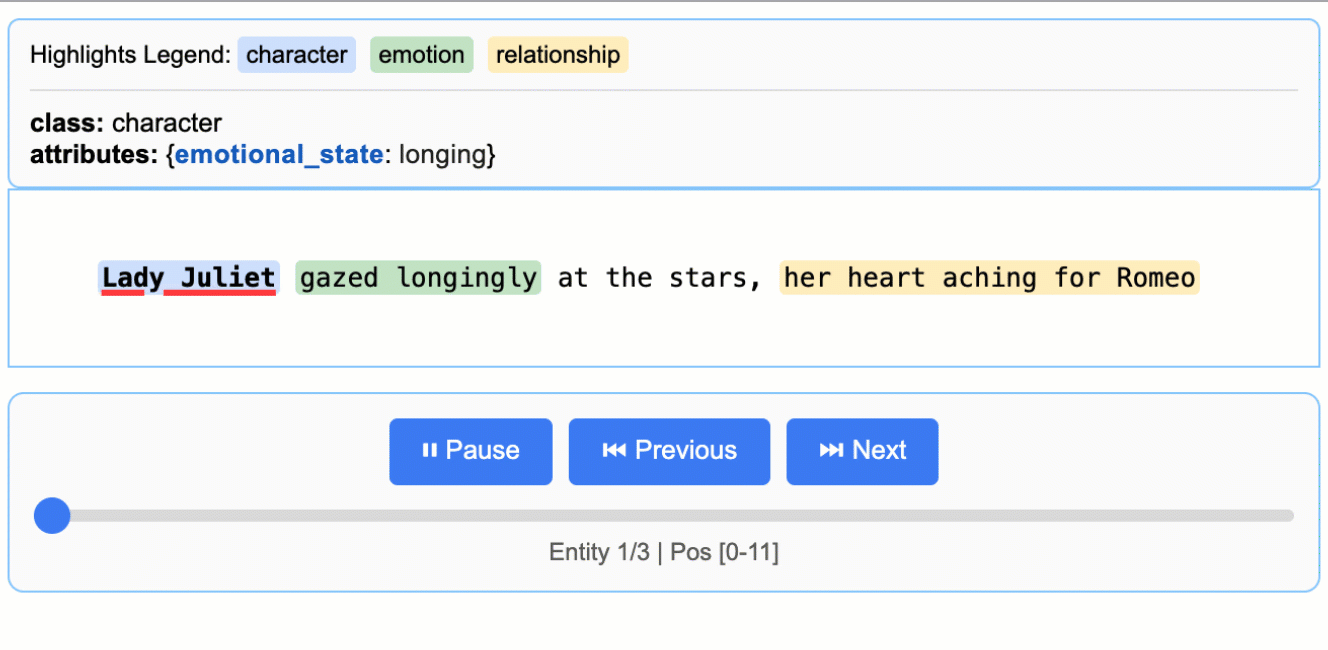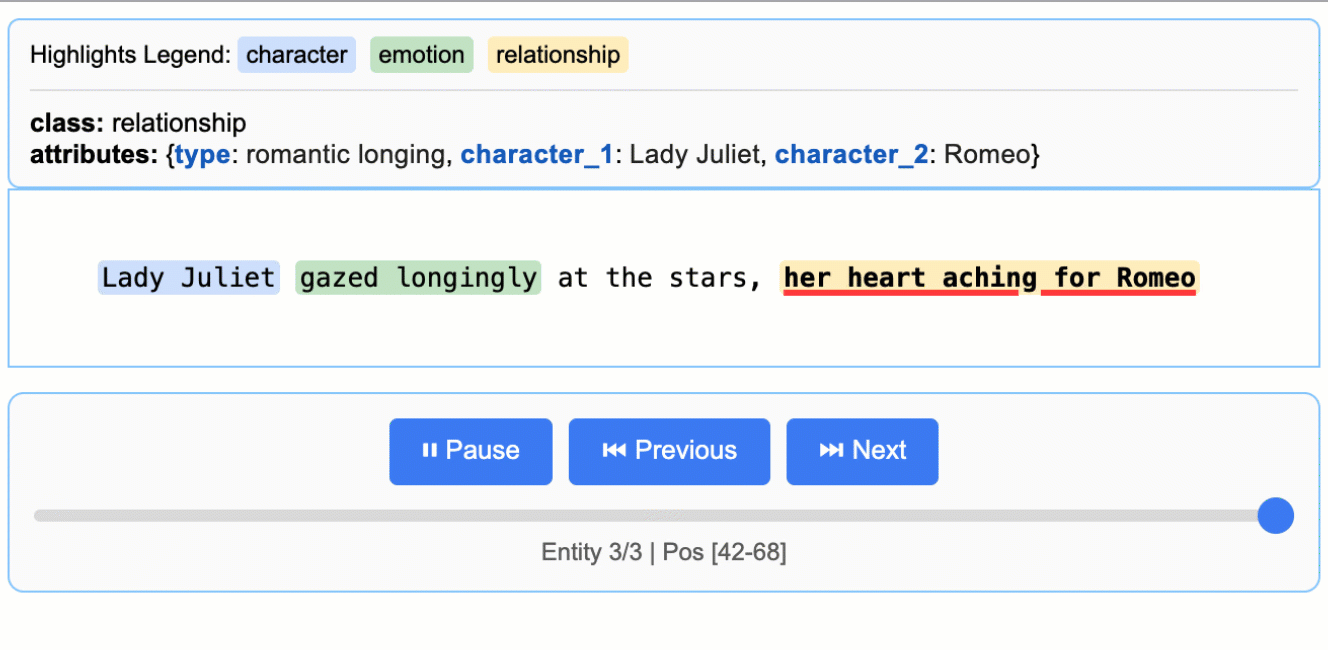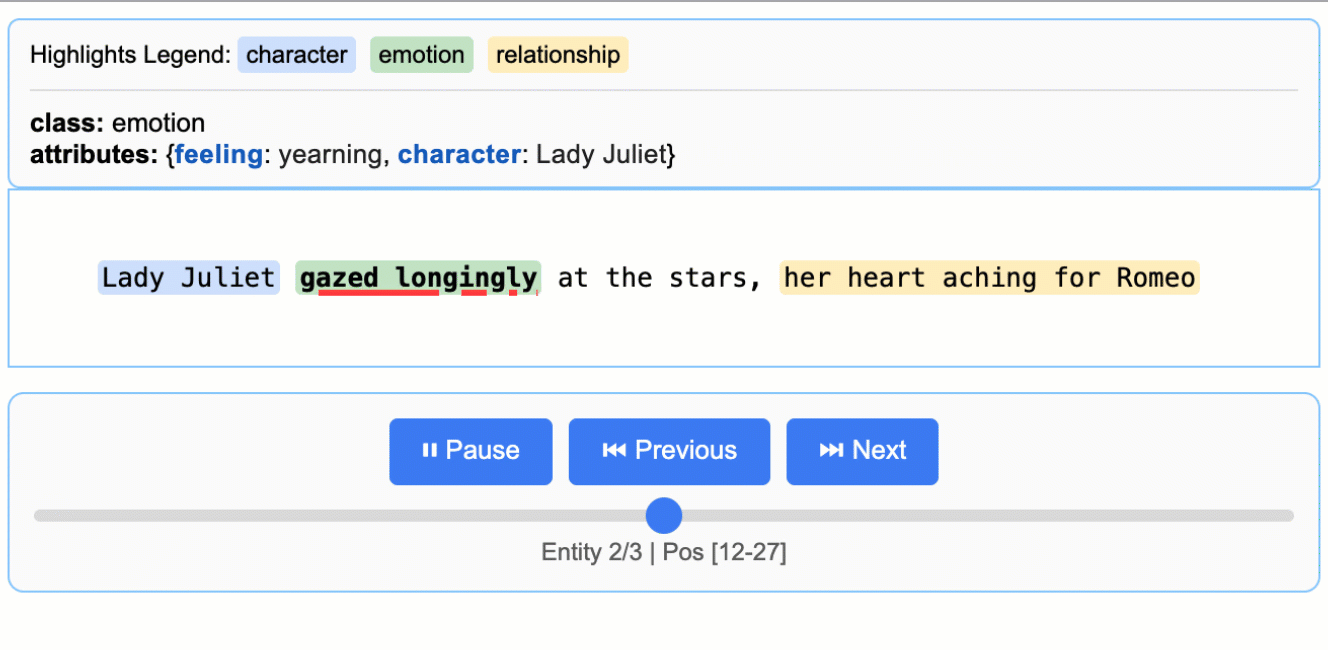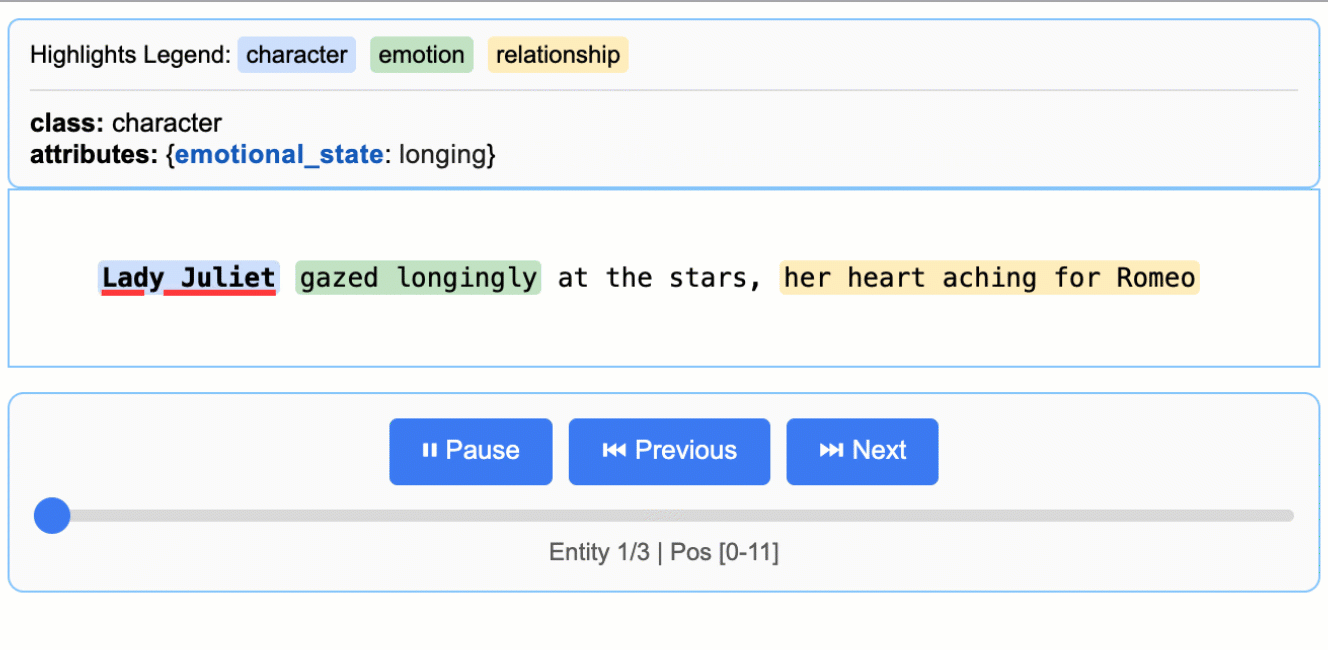
Note on LLM Knowledge Utilization: This example demonstrates extractions that stay close to the text evidence - extracting "longing" for Lady Juliet's emotional state and identifying "yearning" from "gazed longingly at the stars." The task could be modified to generate attributes that draw more heavily from the LLM's world knowledge (e.g., adding
"identity": "Capulet family daughter"or"literary_context": "tragic heroine"). The balance between text-evidence and knowledge-inference is controlled by your prompt instructions and example attributes.
Scaling to Longer Documents
For larger texts, you can process entire documents directly from URLs with parallel processing and enhanced sensitivity:
# Process Romeo & Juliet directly from Project Gutenberg
result = lx.extract(
text_or_documents="https://www.gutenberg.org/files/1513/1513-0.txt",
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
extraction_passes=3, # Improves recall through multiple passes
max_workers=20, # Parallel processing for speed
max_char_buffer=1000 # Smaller contexts for better accuracy
)
This approach can extract hundreds of entities from full novels while maintaining high accuracy. The interactive visualization seamlessly handles large result sets, making it easy to explore hundreds of entities from the output JSONL file. See the full Romeo and Juliet extraction example → for detailed results and performance insights.
Vertex AI Batch Processing
Save costs on large-scale tasks by enabling Vertex AI Batch API: language_model_params={"vertexai": True, "batch": {"enabled": True}}.
See an example of the Vertex AI Batch API usage in this example.
Installation
From PyPI
pip install langextract
Recommended for most users. For isolated environments, consider using a virtual environment:
python -m venv langextract_env
source langextract_env/bin/activate # On Windows: langextract_env\Scripts\activate
pip install langextract
From Source
LangExtract uses modern Python packaging with pyproject.toml for dependency management:
Installing with -e puts the package in development mode, allowing you to modify the code without reinstalling.
git clone https://github.com/google/langextract.git
cd langextract
# For basic installation:
pip install -e .
# For development (includes linting tools):
pip install -e ".[dev]"
# For testing (includes pytest):
pip install -e ".[test]"
Docker
docker build -t langextract .
docker run --rm -e LA
Related Skills
node-connect
325.6kDiagnose OpenClaw node connection and pairing failures for Android, iOS, and macOS companion apps
openai-image-gen
325.6kBatch-generate images via OpenAI Images API. Random prompt sampler + `index.html` gallery.
claude-opus-4-5-migration
80.2kMigrate prompts and code from Claude Sonnet 4.0, Sonnet 4.5, or Opus 4.1 to Opus 4.5
frontend-design
80.2kCreate distinctive, production-grade frontend interfaces with high design quality. Use this skill when the user asks to build web components, pages, or applications. Generates creative, polished code that avoids generic AI aesthetics.
