AugLy
A data augmentations library for audio, image, text, and video.
Install / Use
/learn @facebookresearch/AugLyREADME
AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations. Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
AugLy is a great library to utilize for augmenting your data in model training, or to evaluate the robustness gaps of your model! We designed AugLy to include many specific data augmentations that users perform in real life on internet platforms like Facebook's -- for example making an image into a meme, overlaying text/emojis on images/videos, reposting a screenshot from social media. While AugLy contains more generic data augmentations as well, it will be particularly useful to you if you're working on a problem like copy detection, hate speech detection, or copyright infringement where these "internet user" types of data augmentations are prevalent.
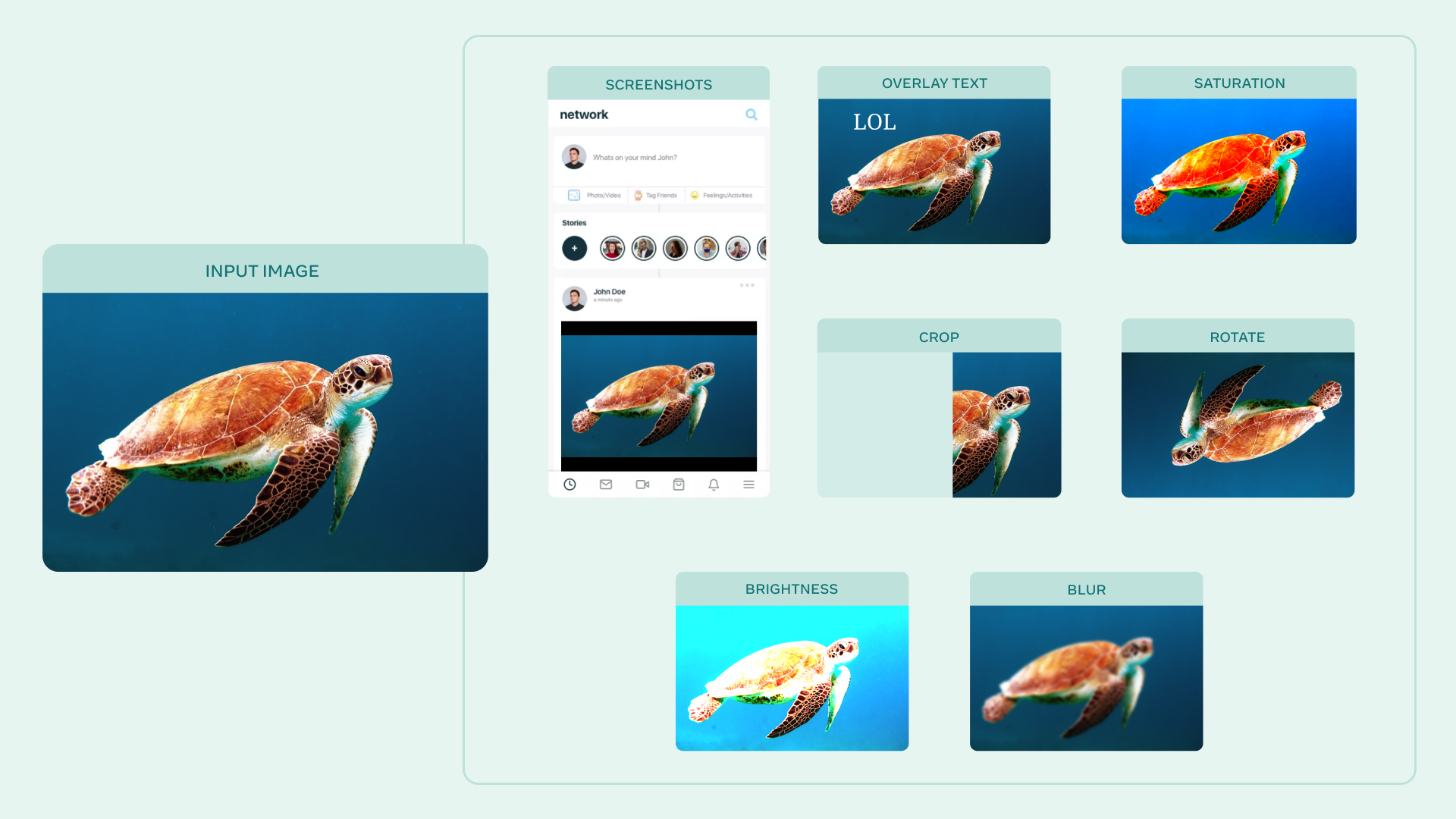
To see more examples of augmentations, open the Colab notebooks in the README for each modality! (e.g. image README & Colab)
The library is Python-based and requires at least Python 3.6, as we use dataclasses.
Authors
Joanna Bitton — Software Engineer at Meta AI
Zoe Papakipos — Software Engineer at Meta AI
Installation
AugLy is a Python 3.6+ library. It can be installed with:
pip install augly[all]
If you want to only install the dependencies needed for one sub-library e.g. audio, you can install like so:
pip install augly[audio]
Or clone AugLy if you want to be able to run our unit tests, contribute a pull request, etc:
git clone git@github.com:facebookresearch/AugLy.git && cd AugLy
[Optional, but recommended] conda create -n augly && conda activate augly && conda install pip
pip install -e .[all]
Backwards compatibility note: In versions augly<=0.2.1 we did not separate the dependencies by modality. For those versions to install most dependencies you could use pip install augly, and if you want to use the audio or video modalities you would install with pip install augly[av].
In some environments, pip doesn't install python-magic as expected. In that case, you will need to additionally run:
conda install -c conda-forge python-magic
Or if you aren't using conda:
sudo apt-get install python3-magic
Documentation
Check out our documentation on ReadtheDocs!
For more details about how to use each sub-library, how to run the tests, and links to colab notebooks with runnable examples, please see the READMEs in each respective directory (audio, image, text, & video).
Assets
We provide various media assets to use with some of our augmentations. These assets include:
- Emojis (Twemoji) - Copyright 2020 Twitter, Inc and other contributors. Code licensed under the MIT License. Graphics licensed under CC-BY 4.0.
- Fonts (Noto fonts) - Noto is a trademark of Google Inc. Noto fonts are open source. All Noto fonts are published under the SIL Open Font License, Version 1.1.
- Screenshot Templates - Images created by a designer at Facebook specifically to use with AugLy. You can use these with the
overlay_onto_screenshotaugmentation in both the image and video libraries to make it look like your source image/video was screenshotted in a social media feed similar to Facebook or Instagram.
Links
- Facebook AI blog post: https://ai.facebook.com/blog/augly-a-new-data-augmentation-library-to-help-build-more-robust-ai-models/
- PyPi package: https://pypi.org/project/augly/
- Arxiv paper: https://arxiv.org/abs/2201.06494
- Examples: https://github.com/facebookresearch/AugLy/tree/main/examples
Uses of AugLy in the wild
- Image Similarity Challenge - a NeurIPS 2021 competition run by Facebook AI with $200k in prizes, currently open for sign ups; also produced the DISC21 dataset, which will be made publicly available after the challenge concludes!
- DeepFake Detection Challenge - a Kaggle competition run by Facebook AI in 2020 with $1 million in prizes; also produced the DFDC dataset
- SimSearchNet - a near-duplicate detection model developed at Facebook AI to identify infringing content on our platforms
Citation
If you use AugLy in your work, please cite our Arxiv paper using the citation below:
@misc{papakipos2022augly,
author = {Zoe Papakipos and Joanna Bitton},
title = {AugLy: Data Augmentations for Robustness},
year = {2022},
eprint = {2201.06494},
archivePrefix = {arXiv},
primaryClass = {cs.AI}}
}
License
AugLy is MIT licensed, as found in the LICENSE file. Please note that some of the dependencies AugLy uses may be licensed under different terms.
Related Skills
qqbot-channel
343.1kQQ 频道管理技能。查询频道列表、子频道、成员、发帖、公告、日程等操作。使用 qqbot_channel_api 工具代理 QQ 开放平台 HTTP 接口,自动处理 Token 鉴权。当用户需要查看频道、管理子频道、查询成员、发布帖子/公告/日程时使用。
docs-writer
99.7k`docs-writer` skill instructions As an expert technical writer and editor for the Gemini CLI project, you produce accurate, clear, and consistent documentation. When asked to write, edit, or revie
model-usage
343.1kUse CodexBar CLI local cost usage to summarize per-model usage for Codex or Claude, including the current (most recent) model or a full model breakdown. Trigger when asked for model-level usage/cost data from codexbar, or when you need a scriptable per-model summary from codexbar cost JSON.
ddd
Guía de Principios DDD para el Proyecto > 📚 Documento Complementario : Este documento define los principios y reglas de DDD. Para ver templates de código, ejemplos detallados y guías paso
