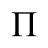TopicModelsVB.jl
A Julia package for variational Bayesian topic modeling.
Install / Use
/learn @ericproffitt/TopicModelsVB.jlREADME
TopicModelsVB.jl
v1.x compatible.
A Julia package for variational Bayesian topic modeling.
Topic models are Bayesian hierarchical models designed to discover the latent low-dimensional thematic structure within corpora. Topic models are fit using either Markov chain Monte Carlo (MCMC), or variational inference (VI).
Markov chain Monte Carlo methods are slow but consistent, given enough time, MCMC will fit the desired model exactly. Contrarily, variational inference is fast but inconsistent, as one must approximate distributions in order to ensure tractability.
This package takes the latter approach to topic modeling.
Installation
(@v1.8) pkg> add https://github.com/ericproffitt/TopicModelsVB.jl
Dependencies
DelimitedFiles
SpecialFunctions
LinearAlgebra
Random
Distributions
OpenCL
Crayons
Datasets
Included in TopicModelsVB.jl are two datasets:
- National Science Foundation Abstracts 1989 - 2003:
- 128804 documents
- 25319 vocabulary
- CiteULike Science Article Database:
- 16980 documents
- 8000 vocabulary
- 5551 users
Corpus
Let's begin with the Corpus data structure. The Corpus data structure has been designed for maximum ease-of-use. Datasets must still be cleaned and put into the appropriate format, but once a dataset is in the proper format and read into a corpus, it can easily be modified to meet the user's needs.
There are four plaintext files that make up a corpus:
- docfile
- vocabfile
- userfile
- titlefile
None of these files are mandatory to read a corpus, and in fact reading no files will result in an empty corpus. However in order to train a model a docfile will be necessary, since it contains all quantitative data known about the documents. On the other hand, the vocab, user and title files are used solely for interpreting output.
The docfile should be a plaintext file containing lines of delimited numerical values. Each document is a block of lines, the number of which depends on what information is known about the documents. Since a document is at its essence a list of terms, each document must contain at least one line containing a nonempty list of delimited positive integer values corresponding to the terms of which it is composed. Any further lines in a document block are optional, however if they are present they must be present for all documents and must come in the following order:
terms - A line of delimited positive integers corresponding to the terms which make up the document (this line is mandatory).
counts - A line of delimited positive integers, equal in length to terms, corresponding to the number of times a term appears in a document.
readers - A line of delimited positive integers corresponding to those users which have read the document.
ratings - A line of delimited positive integers, equal in length to readers, corresponding to the rating each reader gave the document.
An example of a single doc block from a docfile with all possible lines included,
...
4,10,3,100,57
1,1,2,1,3
1,9,10
1,1,5
...
The vocab and user files are tab delimited dictionaries mapping positive integers to terms and usernames (resp.). For example,
1 this
2 is
3 a
4 vocab
5 file
A userfile is identitcal to a vocabfile, except usernames will appear in place of vocabulary terms.
Finally, a titlefile is simply a list of titles, not a dictionary, and is of the form,
title1
title2
title3
title4
title5
The order of these titles correspond to the order of document blocks in the associated docfile.
To read a corpus into Julia, use the following function,
readcorp(;docfile="", vocabfile="", userfile="", titlefile="", delim=',', counts=false, readers=false, ratings=false)
The file keyword arguments indicate the path where the respective file is located.
It is often the case that even once files are correctly formatted and read, the corpus will still contain formatting defects which prevent it from being loaded into a model. Therefore, before loading a corpus into a model, it is important that one of the following is run,
fixcorp!(corp)
or
fixcorp!(corp, pad=true)
Padding a corpus will ensure that any documents which contain vocab or user keys not in the vocab or user dictionaries are not removed. Instead, generic vocab and user keys will be added as necessary to the vocab and user dictionaries (resp.).
The fixcorp! function allows for significant customization of the corpus object.
For example, let's begin by loading the CiteULike corpus,
corp = readcorp(:citeu)
A standard preprocessing step might involve removing stop words, removing terms which appear less than 200 times, and alphabetizing our corpus.
fixcorp!(corp, stop=true, abridge=200, alphabetize=true, trim=true)
## Generally you will also want to trim your corpus.
## Setting trim=true will remove leftover terms from the corpus vocabulary.
After removing stop words and abridging our corpus, the vocabulary size has gone from 8000 to 1692.
A consequence of removing so many terms from our corpus is that some documents may now by empty. We can remove these documents from our corpus with the following command,
fixcorp!(corp, remove_empty_docs=true)
In addition, if you would like to preserve term order in your documents, then you should refrain from condesing your corpus.
For example,
corp = Corpus(Document(1:9), vocab=split("the quick brown fox jumped over the lazy dog"))
showdocs(corp)
●●● Document 1
the quick brown fox jumped over the lazy dog
fixcorp!(corp, condense=true)
showdocs(corp)
●●● Document 1
jumped fox over the quick dog lazy brown the
Important. A corpus is only a container for documents.
Whenever you load a corpus into a model, a copy of that corpus is made, such that if you modify the original corpus at corpus-level (remove documents, re-order vocab keys, etc.), this will not affect any corpus attached to a model. However! Since corpora are containers for their documents, modifying an individual document will affect it in all corpora which contain it. Therefore,
-
Using
fixcorp!to modify the documents of a corpus will not result in corpus defects, but will cause them also to be changed in all other corpora which contain them. -
If you would like to make a copy of a corpus with independent documents, use
deepcopy(corp). -
Manually modifying documents is dangerous, and can result in corpus defects which cannot be fixed by
fixcorp!. It is advised that you don't do this without good reason.
Models
The available models are as follows:
CPU Models
LDA(corp, K)
Latent Dirichlet allocation model with K topics.
fLDA(corp, K)
Filtered latent Dirichlet allocation model with K topics.
CTM(corp, K)
Correlated topic model with K topics.
fCTM(corp, K)
Filtered correlated topic model with K topics.
CTPF(corp, K)
Collaborative topic Poisson factorization model with K topics.
GPU Models
gpuLDA(corp, K)
GPU accelerated latent Dirichlet allocation model with K topics.
gpuCTM(corp, K)
GPU accelerated correlated topic model with K topics.
gpuCTPF(corp, K)
GPU accelerated collaborative topic Poisson factorization model with K topics.
Tutorial
Latent Dirichlet Allocation
Let's begin our tutorial with a simple latent Dirichlet allocation (LDA) model with 9 topics, trained on the first 5000 documents from the NSF corpus.
using TopicModelsVB
using Random
using Distributions
Random.seed!(7);
corp = readcorp(:nsf)
corp.docs = corp[1:5000];
fixcorp!(corp, trim=true)
## It's strongly recommended that you trim your corpus when reducing its size in order to remove excess vocabulary.
## Notice that the post-fix vocabulary is smaller after removing all but the first 5000 docs.
model = LDA(corp, 9)
train!(model, iter=150, tol=0)
## Setting tol=0 will ensure that all 150 iterations are completed.
## If you don't want to compute the ∆elbo, set checkelbo=Inf.
## training...
showtopics(model, cols=9, 20)
topic 1 topic 2 topic 3 topic 4 topic 5 topic 6 topic 7 topic 8 topic 9
research system data theory research research research research plant
problems research earthquake study university data project study cell
design data project problems support project study chemistry species
systems systems research research students study data high protein
algorithms control study equations program ocean social studies cells
parallel time soil work science water understanding properties plants
data design damage investigator award studies economic chemical studies
project project seismic principal scientists processes important materials research
based analysis response project dr provide information structure genetic
models processing structures geometry sciences field policy program gene
model solar sites mathematical projects time development surface study
system computer ground systems conference important w