MoneyPrinterPlus
AI一键批量生成各类短视频,自动批量混剪短视频,自动把视频发布到抖音,快手,小红书,视频号上,赚钱从来没有这么容易过! 支持本地语音模型chatTTS,fasterwhisper,GPTSoVITS,支持云语音:Azure,阿里云,腾讯云。支持Stable diffusion,comfyUI直接AI生图。Generate short videos with one click using AI LLM,print money together! support:chatTTS,faster-whisper,GPTSoVITS,Azure,tencent Cloud,Ali Cloud.
Install / Use
/learn @ddean2009/MoneyPrinterPlusREADME
这是一个轻松赚钱的项目。
短视频时代,谁掌握了流量谁就掌握了Money!
所以给大家分享这个经过精心打造的MoneyPrinter项目。
它可以:使用AI大模型技术,一键批量生成各类短视频。
它可以:一键混剪短视频,批量生成短视频不是梦。
它可以:自动把视频发布到抖音,快手,小红书,视频号上。
赚钱从来没有这么容易过!
觉得有用的朋友,请给个star! 
目录
视频教程
MoneyPrinterPlus一键AI短视频生成工具开源啦
MoneyPrinterPlus AI批量短视频混剪工具使用说明
MoneyPrinterPlus小白使用教程来啦!一键万条短视频
MoneyPrinterPlus一键批量上传视频功能来啦,让收费见鬼去吧!
MoneyPrinterPlus全面支持本地chatTTS模型
MoneyPrinterPlus无缝对接GPT-SoVITS
图文系列教程
MoneyPrinterPlus一键发布短视频到视频号,抖音,快手,小红书上线了
MoneyPrinterPlus全面支持本地Ollama大模型
在MoneyPrinterPlus中使用本地chatTTS语音模型
fasterWhisper和MoneyPrinterPlus无缝集成
再升级!MoneyPrinterPlus集成GPT_SoVITS
界面概览
1. AI视频批量混剪工具
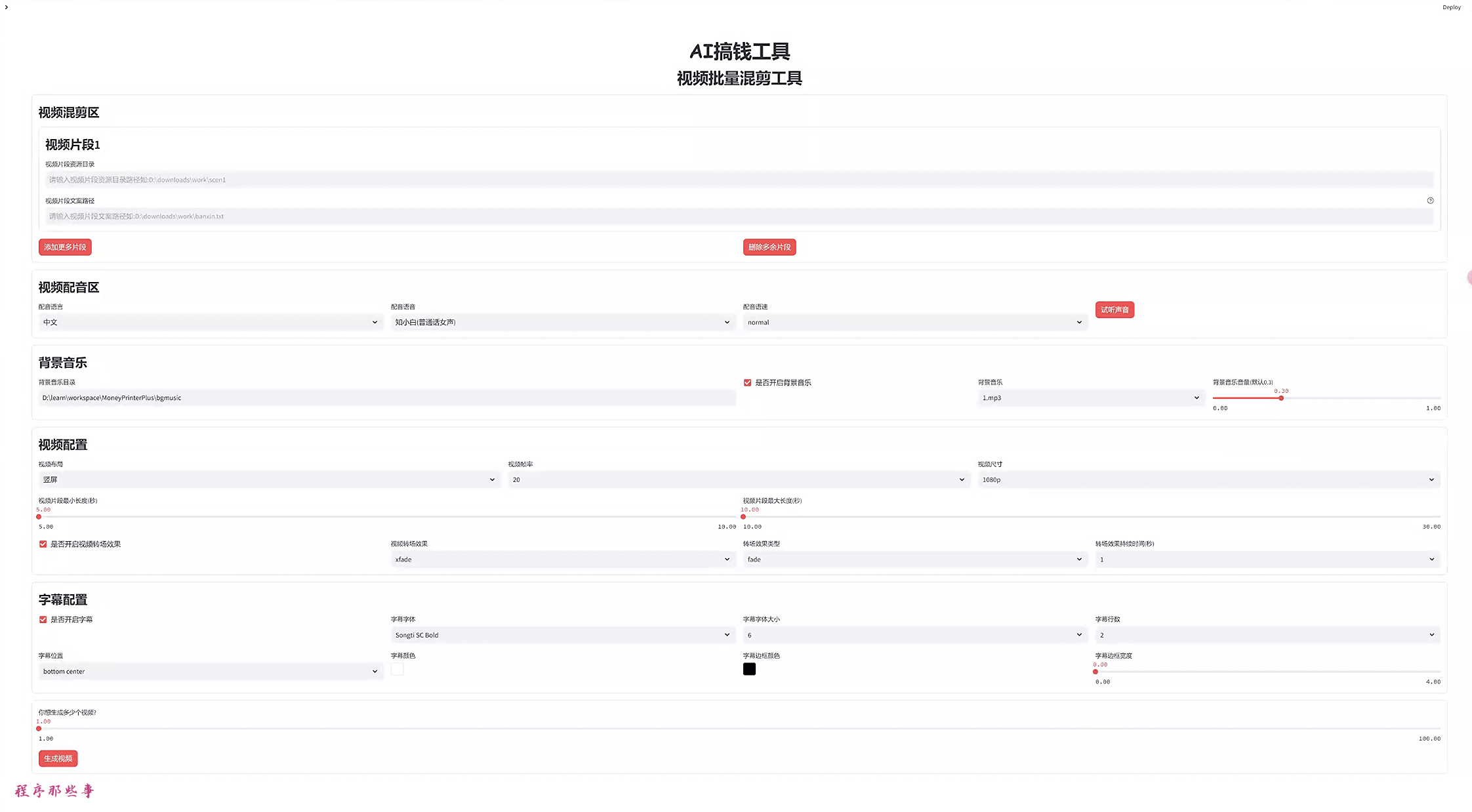
使用介绍: 重磅!免费一键批量混剪工具它来了,一天上万短视频不是梦
2. AI视频生成器
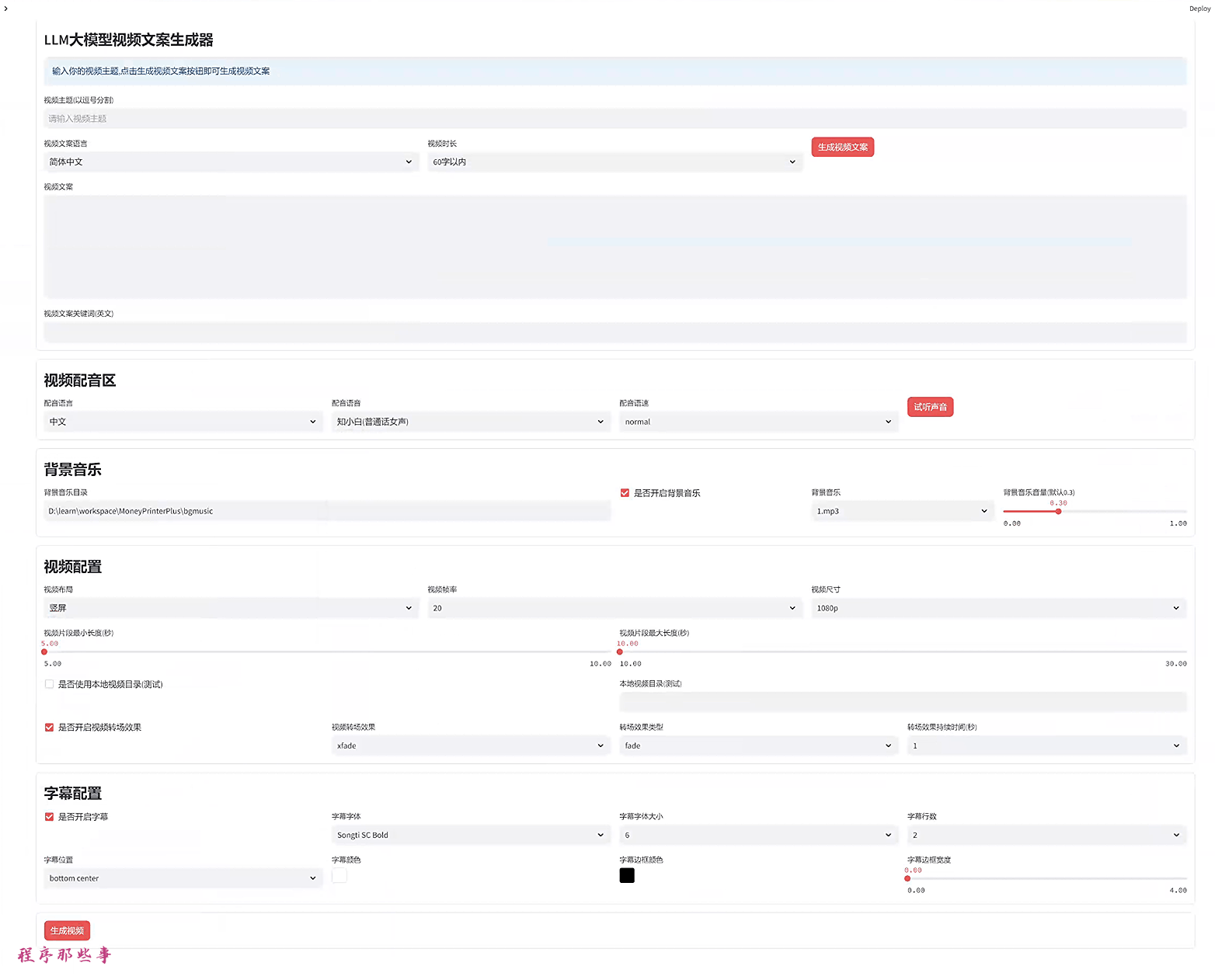
使用介绍: moneyPrinterPlus详细使用教程
3. 批量视频自动上传工具


MoneyPrinterPlus一键发布短视频到视频号,抖音,快手,小红书上线了
更新预告
- 准备接入stable diffusion和comfyUI, OOOOO,太牛了!
- 新增对接cosyvoice语言生成和sensevoice字幕生成。
- 已经支持GPTsoVITS本地语音模型啦,教程再升级!MoneyPrinterPlus集成GPT_SoVITS
- 已经支持本地语音识别模型fasterwhisper, 教程fasterWhisper和MoneyPrinterPlus无缝集成。 可关注我公众号获得最新进度。
- 已经支持本地语音模型ChatTTS了,教程 在MoneyPrinterPlus中使用本地chatTTS语音模型
- 支持本地大模型工具Ollama MoneyPrinterPlus全面支持本地Ollama大模型
- 视频自动发布功能已经上线了!!!! 使用教程MoneyPrinterPlus一键发布短视频到视频号,抖音,快手,小红书上线了
更新列表
- 20250208 新增对接cosyvoice语言生成和sensevoice字幕生成。
- 20241116 添加合并视频功能。不需要配置语音了,只是单纯的进行视频合并。
- 20240927 添加docker file,感谢子涵同学提供的dockerfile文件。
- 20240905 从V4.5版本开始,提供了小白版的windows版本,大家不需要设置python,ffmpeg环境了.只需要解压缩:1.双击setup.bat. 2.双击start.bat即可运行。
- 20240813 支持GPTsoVITS本地语音模型
- 20240807 存储了session值,这样在刷新的时候不需要重新输入信息了
- 20240722 支持本地语音识别模型fasterwhisper
- 20240713 支持本地语音模型ChatTTS
- 20240710 支持本地大模型:Ollama
- 20240708 逆天了!自动发布视频功能上线了。支持抖音,快手,小红书,视频号!!!
- 20240704 添加自动安装和自动启动脚本,方便小白使用。
- 20240628 重磅更新!支持批量视频混剪,批量生成大量不重复的短视频!!!!!!
- 20240620 优化视频合成效果,让视频结束更加自然。
- 20240619 语音识别和语音合成支持腾讯云。 需要开通腾讯云语音合成和语音识别这两个功能
- 20240615 语音识别和语音合成支持阿里云。 需要开通阿里云智能语音交互功能--必须开通语音合成和录音文件识别(极速版)这两个功能
- 20240614 资源库支持pixabay,支持语音试听功能,修复一些bug
已实现功能
- [x] 支持本地语音模型chatTTS, fasterwhisper等
- [x] 支持本地语音字幕识别模型
- [x] 视频批量自动发布到各个视频平台,支持抖音,快手,小红书,视频号!!!
- [x] 视频批量混剪,批量产出大量不重复的短视频
- [x] 支持本地视频合并功能
- [x] 支持本地素材选择(支持各种素材mp4,jpg,png),支持各种分辨率。
- [x] 云大模型接入OpenAI,Azure,Kimi,Qianfan,Baichuan,Tongyi Qwen, DeepSeek
- [x] 本地大模型接入Ollama
- [x] 支持Azure语音功能
- [x] 支持阿里云语音功能
- [x] 支持腾讯云语音功能
- [x] 支持100+不同的语音种类
- [x] 支持语音试听功能
- [x] 支持30+种视频转场特效
- [x] 支持不同分辨率,不同尺寸和比例的视频生成
- [x] 支持语音选择和语速调节
- [x] 支持背景音乐
- [x] 支持背景音乐音量调节
- [x] 支持自定义字幕
- [x] 覆盖市面上主流的AI大模型工具
待实现功能
- [] 支持更多的视频资源获取方式
- [] 支持更多的视频转场特效
- [] 支持更多的字幕特效
- [] 接入stable diffusion,AI生图,合成视频
- [] 接入Sora等AI视频大模型工具,自动生成视频
实例展示
<table> <thead> <tr> <th align="center">竖屏</th> <th align="center">横屏</th> <th align="center">正方形</th> </tr> </thead> <tr> <td align="center"><video src="https://github.com/ddean2009/MoneyPrinterPlus/assets/13955545/d96e5e50-cfe7-4f55-a0db-75f3ac28b39f"></video></td> <td align="center"><video src="https://github.com/ddean2009/MoneyPrinterPlus/assets/13955545/714b122d-d857-4132-bdd3-9f07c9aa787b"></video></td> <td align="center"><video src="https://github.com/ddean2009/MoneyPrinterPlus/assets/13955545/2ec748c2-8145-4178-ae48-a3114290addd"></video></td> </tr> </table>使用方法
环境要求
- Python 3.10,3.11 安装包: https://www.python.org/ftp/python/3.11.8/python-3.11.8-amd64.exe
- ffmpeg 6.1.1 安装包:https://www.gyan.dev/ffmpeg/builds/packages/ffmpeg-6.1.1-essentials_build.zip
- windows 必须安装VC: https://aka.ms/vs/17/release/vc_redist.x64.exe
- 从V4.5版本开始,提供了小白版的windows版本,大家不需要设置python,ffmpeg环境了.只需要解压缩:1.双击安装vc_redist.x64.exe 2.双击setup.bat. 3.双击start.bat即可运行。
- LLM api key
- Azure语音服务(https://speech.microsoft.com/portal)
- 或者阿里云智能语音功能(https://nls-portal.console.aliyun.com/overview)
- 或者腾讯云语音技术功能(https://console.cloud.tencent.com/asr)
切记!!!!! 一定要安装好ffmpeg,并把ffmpeg路径添加到环境变量中。
安装
前提条件
- 确保你有Python 3.10+的运行环境。如果是windows, 请确保安装了python路径已经添加到了PATH中。
- 确保你有ffmpeg 6.0+的运行环境。如果是windows, 请确保安装了ffmpeg路径已经添加到了PATH中。没有安装ffmpeg的朋友,请通过 https://ffmpeg.org/ 来安装对应的版本。
从V4.5版本开始,提供了小白版的windows版本,大家不需要设置python,ffmpeg环境了.只需要解压缩:1.双击安装vc_redist.x64.exe 2.双击setup.bat. 3.双击start.bat即可运行。
手动安装
如果python和ffmpeg环境都有了。那么就可以通过pip安装依赖包了。
pip install -r requirements.txt
自动安装
进入项目目录,windows下双击执行:
setup.bat
mac或者linux下执行:
bash setup.sh
运行
使用下面命令运行程序:
streamlit run gui.py
自动运行
如果你使用了自动安装脚本,那么可以执行下面的脚本来自动运行。
windows下,双击 start.bat
mac或者linux下执行:
bash start.sh
在日志文件中可以看到程序运行的日志信息。
里面有浏览器的地址,可以通过浏览器打开这个地址来访问程序。
打开之后,你会看到下面的界面:
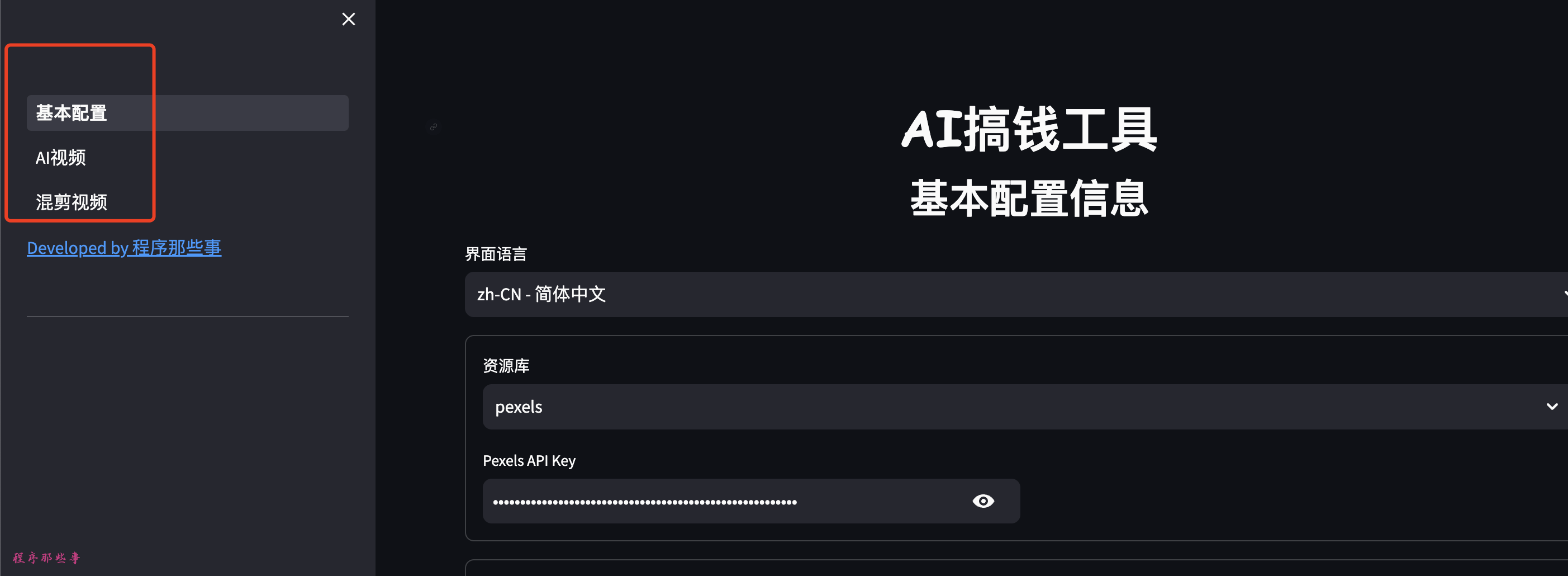
左侧目前有三项配置, 分别是基本配置,AI视频和混剪视频(开发中)。
基本配置
1. 资源库
目前资源支持:
- pexels: www.pexels.com Pexels 是世界上著名的免费图片,视频素材网站。
- pixabay: pixabay.com
大家需要到对应的网站上注册一个key来实现API调用。
后续会陆续添加其他资源库。如(videvo.net,videezy.com 等)
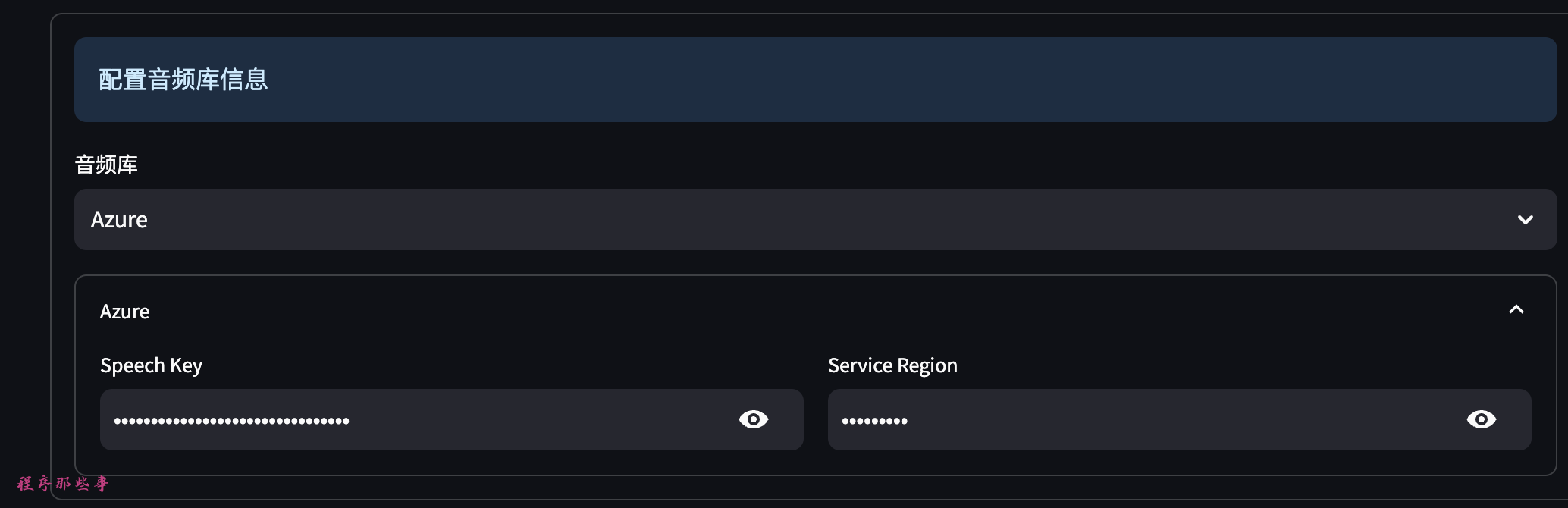
2. 音频库
目前文字转语音和语音识别功能支持:
- Azure的cognitive-services服务。
- 阿里云的智能语音交互
- 腾讯云语音技术功能(https://console.cloud.tencent.com/asr)
- Azure:
大家需要到 https://speech.microsoft.com/portal 这里注册一个key。
Azure对新用户是1年免费的。费用也是比较便宜。
- 阿里云:
大家需要到 https://nls-portal.console.aliyun.com/overview 这里开通服务,并添加一个项目。
需要开通阿里云智能语音交互功能--必须开通语音合成和录音文件识别(极速版)这两个功能.
- 腾讯云:
腾讯云语音技术功能(https://console.cloud.tencent.com/asr) 开通语音识别和语音合成功能。
后续会添加本地语音识别大模型。但是文字转语音还是微软的服务最为优秀。
3. LLM大模型
大模型区目前支持Moonshot,openAI,Azure openAI,Baidu Qianfan, Baichuan,Tongyi Qwen, DeepSeek这些。
推荐使用Moonshot。
会陆续添加市面上其他流行的大模型。
Moonshot API获取地址: https://platform.moonshot.cn/
baidu qianfan API获取地址:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/yloieb01t
baichuan API获取地址: htt
Related Skills
openhue
335.4kControl Philips Hue lights and scenes via the OpenHue CLI.
sag
335.4kElevenLabs text-to-speech with mac-style say UX.
weather
335.4kGet current weather and forecasts via wttr.in or Open-Meteo
tweakcc
1.4kCustomize Claude Code's system prompts, create custom toolsets, input pattern highlighters, themes/thinking verbs/spinners, customize input box & user message styling, support AGENTS.md, unlock private/unreleased features, and much more. Supports both native/npm installs on all platforms.
