EXpath
Repository for VLDB2025 paper "eXpath: Explaining Knowledge Graph Link Prediction with Ontological Closed Path Rules"
Install / Use
/learn @cs-anonymous/EXpathREADME
eXpath: Explaining Knowledge Graph Link Prediction with Ontological Closed Path Rules
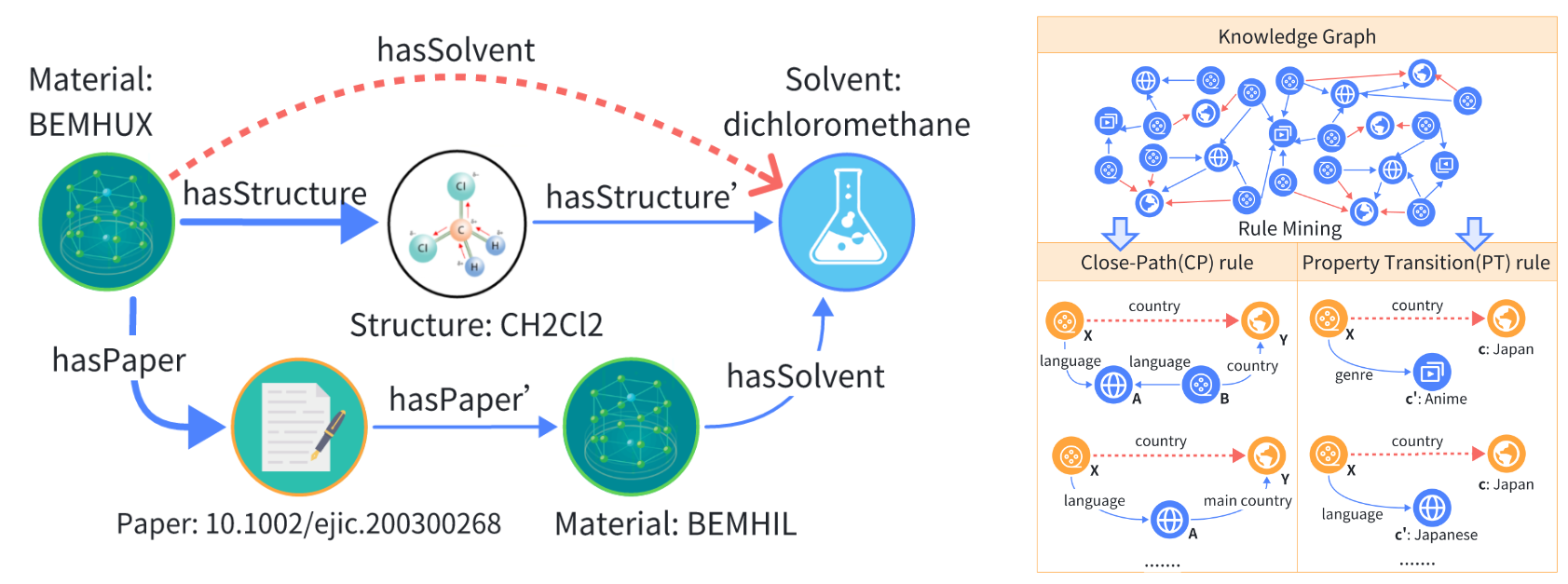
eXpath is a novel framework designed to enhance the interpretability of Link Prediction (LP) models in Knowledge Graphs (KG). While existing methods have successfully addressed LP in KGs, they often fall short in terms of providing semantically meaningful and human-interpretable explanations. eXpath tackles this issue by introducing path-based explanations that incorporate ontological closed path rules. This approach not only improves the efficiency and effectiveness of LP interpretation but also enables a more semantically rich understanding of the predicted links. The primary contributions include:
- Path-based Explanations: Unlike traditional methods that focus on single-hop explanations, eXpath detects multi-hop paths within KGs, providing causal and context-based relationships. For instance, in material KGs, eXpath can explain synthesized materials in a particular solvent by detecting relevant paths that capture deeper relationships between entities.
- Ontological Closed Path Rules: eXpath integrates ontology theory to strengthen the semantics of path-based explanations. By leveraging closed path and property transition rules, eXpath ensures that the explanations are both semantically consistent and computationally efficient.
- Evaluation: Extensive experiments across benchmark datasets show that eXpath improves the quality of LP explanations by approximately 20%, while also reducing the explanation time by 61.4% compared to existing methods. Case studies demonstrate how eXpath provides more meaningful explanations for real-world scenarios.
Review and response can be found in the wiki page.
eXpath Structure:
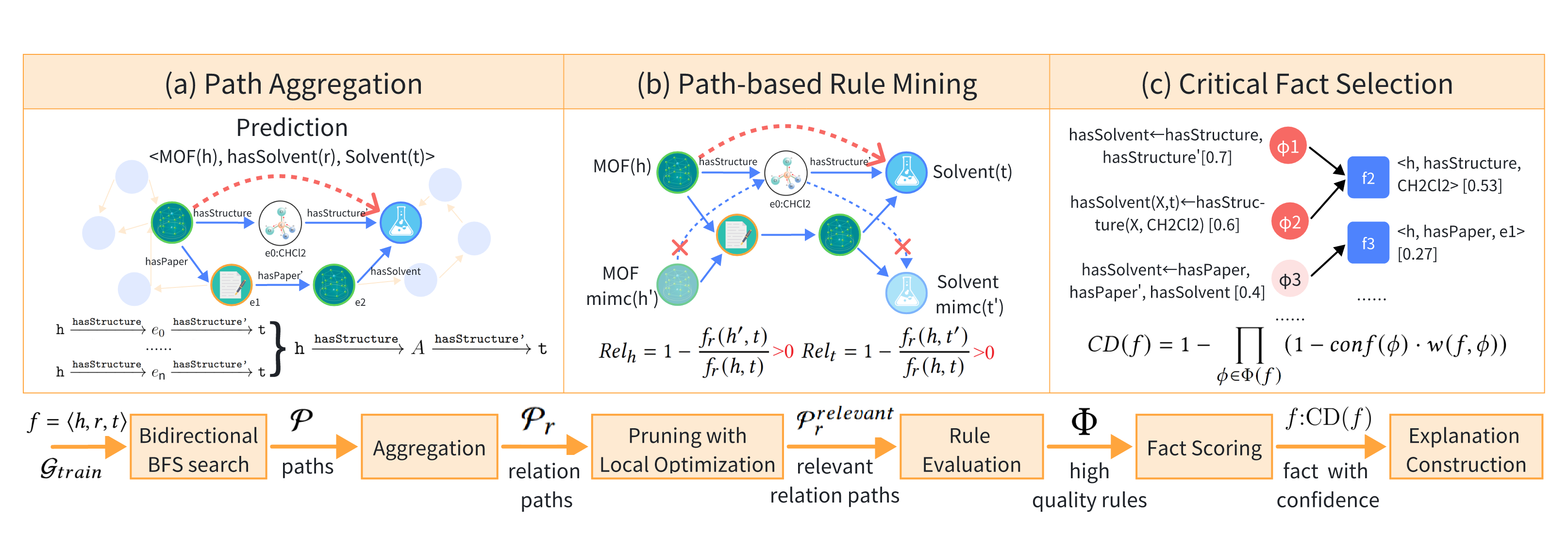
The eXpath framework consists of a three-stage process designed to generate path-based explanations for Knowledge Graph Link Prediction (KGLP) tasks. Below is a detailed overview of each component in the framework.
1. Path Aggregation Stage
In the path aggregation stage, eXpath identifies potential paths connecting the head entity hh to the tail entity tt in the knowledge graph (KG). A breadth-first search (BFS) is employed to extract paths up to a maximum length of 3 for interpretability. These paths are then transformed into "relation paths" by removing intermediate entities, reducing the total number of paths while preserving their semantic relevance. This abstraction ensures computational efficiency and focuses on the relationships rather than individual nodes.
2. Path-Based Rule Mining Stage
This stage focuses on extracting meaningful rules from the relation paths identified in the previous step. Two types of ontological rules are considered:
- Closed Path (CP) Rules: These represent sequences of relations that form closed loops, connecting hh and tt via multiple intermediary relations.
- Property Transition (PT) Rules: These describe attribute-based relationships between entities, such as correlations between specific properties.
Relevant relation paths are selected using local optimization techniques, where the relevance scores of head and tail entities are computed. High-confidence CP and PT rules are retained based on their support (supp), standard confidence (SC), and head coverage (HC). These metrics evaluate how consistently a rule generalizes across the dataset.
3. Critical Fact Selection Stage
In the final stage, eXpath selects the most critical facts that contribute to the prediction explanation. Each candidate fact is scored based on the number and confidence of the rules it satisfies. The scoring process considers:
- Rule Count: Facts that satisfy multiple rules receive higher scores.
- Confidence Weight: Rules with higher confidence contribute more significantly to a fact’s score.
- Relation Relevance: The importance of the relations linking the head and tail entities influences the fact’s final score.
A "Noisy-OR" aggregation approach is used to compute the confidence degree (CD) of each fact, combining contributions from multiple rules. The highest-ranking facts form the final explanation.
Environment and Prerequisites
We have run all our experiments on an Ubuntu 22.04 environment using Python 3.8.8, CUDA Version: 12.6 and Driver Version: 560.35.03. eXpath requires the following libraries:
- PyTorch (we used version 2.4.1+cu124);
- numpy;
- pandas;
- tqdm;
- matplotlib;
Models and Datasets
eXpath is designed to support any Link Prediction model that relies on embeddings. For simplicity, our implementation focuses on models that train on individual facts, as these are the most commonly used in existing literature. However, eXpath is flexible and can be extended to generate fact-based explanations for models that incorporate contextual information, such as paths, types, or temporal data.
In our experiments, we evaluate three distinct models: ComplEx, ConvE, and TransE, each with different underlying architectures. Implementations for these models are included in this repository. We generate explanations for their predictions on four widely-used datasets: FB15k, WN18, FB15k-237, and WN18RR. The training, validation, and test sets for these datasets are provided in the data folder.
To ensure reproducibility, we have made the trained models available through FigShare. After downloading the stored_models.tar.gz and out.tar.gz files, users can extract them to obtain the stored_models and out directories, respectively.
The explanation generation results are stored in the out folder, while the models can be accessed in the stored_models folder.
For our models and datasets we use hyperparameters defined in config.yaml. Notice that we reduced the number of epochs for four settings to avoid an impractically long experimental duration (which would have required several months). This underfitting led to some degradation in LP metrics for these settings but does not affect the fairness of the explanations since the adversarial LP explanation experiments maintain identical training parameters before and after removing facts.
Paper Experiments Results (Paper Tables 2 and 3)
All the results reported in our paper can be replicated by running End-to-end Experiments:
# run verification on baseline method after their expanations are generated
# baseline method: kelpie criage data_poisoning k1 KGEAttack kex1 kex
./run_baseline.sh
# run verification on eXpath method
./run_main_experiments.sh
# calculate δH@1 and δMRR based on output details
python calculate_metric.py
Future Work

Future work will focus on developing interactive visualization tools to enhance the accessibility and interpretability of eXpath's path-based explanations. These tools will allow users to explore critical paths and ontological rules supporting each prediction, providing a more intuitive understanding of the underlying reasoning. Building on this, we plan to conduct a user study involving domain experts and data scientists to evaluate the clarity, relevance, and actionability of the explanations. This study will quantify the alignment of path-based explanations with human reasoning and assess their effectiveness in improving trust and transparency in KG predictions.
Related Skills
node-connect
351.8kDiagnose OpenClaw node connection and pairing failures for Android, iOS, and macOS companion apps
frontend-design
110.9kCreate distinctive, production-grade frontend interfaces with high design quality. Use this skill when the user asks to build web components, pages, or applications. Generates creative, polished code that avoids generic AI aesthetics.
openai-whisper-api
351.8kTranscribe audio via OpenAI Audio Transcriptions API (Whisper).
qqbot-media
351.8kQQBot 富媒体收发能力。使用 <qqmedia> 标签,系统根据文件扩展名自动识别类型(图片/语音/视频/文件)。
