ParaAttention
https://wavespeed.ai/ Context parallel attention that accelerates DiT model inference with dynamic caching
Install / Use
/learn @chengzeyi/ParaAttentionREADME
ParaAttention
Blazing Fast FLUX-dev with LoRAs
Blazing Fast Wan 2.1 T2V with LoRAs
Blazing Fast Wan 2.1 I2V with LoRAs
Context parallel attention that accelerates DiT model inference with dynamic caching, supporting both Ulysses Style and Ring Style parallelism.
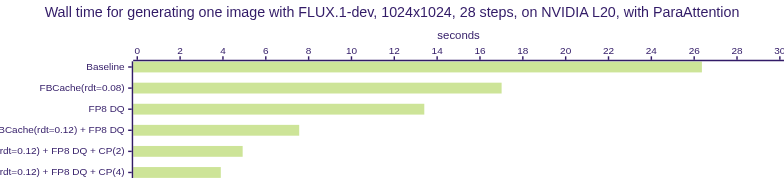
🔥Fastest FLUX.1-dev Inference with Context Parallelism and First Block Cache on NVIDIA L20 GPUs🔥
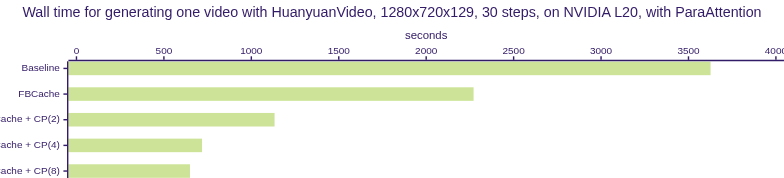
🔥Fastest HunyuanVideo Inference with Context Parallelism and First Block Cache on NVIDIA L20 GPUs🔥
This aims to provide:
- [x] An easy to use interface to speed up model inference with context parallel, dynamic caching and
torch.compile. MakeFLUX,HunyuanVideoandMochiinference much faster losslessly. - [x] A unified interface to run context parallel attention (cfg-ulysses-ring), as well as keeping the maximum performance while working with
torch.compile - [ ] The fastest accurate attention implemented in Triton, running 50% faster than the originial FA2 implementation on RTX 4090.
What's different from other implementations:
- No unnecessary graph breaks during
torch.compile. All the heavy computations are captured in a single graph and get the maximum opportunity to be optimized. This makes it possible for the backend compiler to optimize the graph more effectively, for example, by overlapping the computation and communication. - Easy to use. You don't need to change the code of the model to enable context parallelism. Instead, you only need to call a function to parallelize the model.
- Easy to use, too. If you want to use context parallelism with your custom model, you only need to wrap the call with our special
TorchFunctionModecontext manager. - Easy to adjust. You can adjust the parallelism style and the mesh shape with a few lines of code.
Key Features
Context Parallelism
Context Parallelism (CP) is a method for parallelizing the processing of neural network activations across multiple GPUs by partitioning the input tensors along the sequence dimension.
Unlike Sequence Parallelism (SP) that partitions the activations of specific layers, CP divides the activations of all layers.
In ParaAttention, we are able to parallelize the attention layer with a mixture of Ulysses Style and Ring Style parallelism, called Unified Attention.
This allows us to achieve the best performance with different models and different hardware configurations.
We also provide a unified interface to parallelize the model inference.
You only need to call a single function to enable context parallelism on your diffusers pipeline:
from para_attn.context_parallel.diffusers_adapters import parallelize_pipe
parallelize_pipe(pipe)
First Block Cache (Our Dynamic Caching)
Inspired by TeaCache and other denoising caching algorithms, we introduce First Block Cache (FBCache) to use the residual output of the first transformer block as the cache indicator. If the difference between the current and the previous residual output of the first transformer block is small enough, we can reuse the previous final residual output and skip the computation of all the following transformer blocks. This can significantly reduce the computation cost of the model, achieving a speedup of up to 2x while maintaining high accuracy.
Optimizations for FLUX Image Generation Model on a Single NVIDIA L20 GPU
| Optimizations | Original | FBCache rdt=0.06 | FBCache rdt=0.08 | FBCache rdt=0.10 | FBCache rdt=0.12 |
| - | - | - | - | - | - |
| Preview |  |
|  |
|  |
|  |
|  |
| Wall Time (s) | 26.36 | 21.83 | 17.01 | 16.00 | 13.78 |
|
| Wall Time (s) | 26.36 | 21.83 | 17.01 | 16.00 | 13.78 |
Optimizations for Video Models
| Model | Optimizations | Preview | | - | - | - | | HunyuanVideo | Original | Original | | HunyuanVideo | FBCache | FBCache |
You only need to call a single function to enable First Block Cache on your diffusers pipeline:
from para_attn.first_block_cache.diffusers_adapters import apply_cache_on_pipe
apply_cache_on_pipe(
pipe,
# residual_diff_threshold=0.0,
)
Adjust the residual_diff_threshold to balance the speedup and the accuracy.
Higher residual_diff_threshold will lead to more cache hits and higher speedup, but might also lead to a higher accuracy drop.
Officially Supported Models
Context Parallelism with First Block Cache
You could run the following examples with torchrun to enable context parallelism with dynamic caching.
You can modify the code to enable torch.compile to further accelerate the model inference.
If you want quantization, please refer to diffusers-torchao for more information.
For example, to run FLUX with 2 GPUs:
Note: To measure the performance correctly with torch.compile, you need to warm up the model by running it for a few iterations before measuring the performance.
# Use --nproc_per_node to specify the number of GPUs
torchrun --nproc_per_node=2 parallel_examples/run_flux.py
Single GPU Inference with First Block Cache
You can also run the following examples with a single GPU and enable the First Block Cache to speed up the model inference.
python3 first_block_cache_examples/run_hunyuan_video.py
NOTE: To run HunyuanVideo, you need to install diffusers from its latest master branch.
It is suggested to run HunyuanVideo with GPUs with at least 48GB memory, or you might experience OOM errors,
and the performance might be worse due to frequent memory re-allocation.
Performance
Context Parallelism (without First Block Cache)
| Model | GPU | Method | Wall Time (s) | Speedup |
| --- | --- | --- | --- | --- |
| FLUX.1-dev | A100-SXM4-80GB | Baseline | 13.843 | 1.00x |
| FLUX.1-dev | A100-SXM4-80GB | torch.compile | 9.997 | 1.38x |
| FLUX.1-dev | A100-SXM4-80GB x 2 | para-attn (ring) | 8.307 | 1.66x |
| FLUX.1-dev | A100-SXM4-80GB x 2 | para-attn (ring) + torch.compile | 5.775 | 2.39x |
| FLUX.1-dev | A100-SXM4-80GB x 4 | para-attn (ulysses + ring) | 6.157 | 2.25x |
| FLUX.1-dev | A100-SXM4-80GB x 4 | para-attn (ulysses + ring) + torch.compile | 3.557
Related Skills
qqbot-channel
351.2kQQ 频道管理技能。查询频道列表、子频道、成员、发帖、公告、日程等操作。使用 qqbot_channel_api 工具代理 QQ 开放平台 HTTP 接口,自动处理 Token 鉴权。当用户需要查看频道、管理子频道、查询成员、发布帖子/公告/日程时使用。
docs-writer
100.5k`docs-writer` skill instructions As an expert technical writer and editor for the Gemini CLI project, you produce accurate, clear, and consistent documentation. When asked to write, edit, or revie
model-usage
351.2kUse CodexBar CLI local cost usage to summarize per-model usage for Codex or Claude, including the current (most recent) model or a full model breakdown. Trigger when asked for model-level usage/cost data from codexbar, or when you need a scriptable per-model summary from codexbar cost JSON.
Design
Campus Second-Hand Trading Platform \- General Design Document (v5.0 \- React Architecture \- Complete Final Version)1\. System Overall Design 1.1. Project Overview This project aims t
