Ultraopt
Distributed Asynchronous Hyperparameter Optimization better than HyperOpt. 比HyperOpt更强的分布式异步超参优化库。
Install / Use
/learn @auto-flow/UltraoptREADME

![]()



![]()
UltraOpt : Distributed Asynchronous Hyperparameter Optimization better than HyperOpt.
UltraOpt is a simple and efficient library to minimize expensive and noisy black-box functions, it can be used in many fields, such as HyperParameter Optimization(HPO) and
Automatic Machine Learning(AutoML).
After absorbing the advantages of existing optimization libraries such as
HyperOpt<sup>[5]</sup>, SMAC3<sup>[3]</sup>,
scikit-optimize<sup>[4]</sup> and HpBandSter<sup>[2]</sup>, we develop
UltraOpt , which implement a new bayesian optimization algorithm : Embedding-Tree-Parzen-Estimator(ETPE), which is better than HyperOpt' TPE algorithm in our experiments.
Besides, The optimizer of UltraOpt is redesigned to adapt HyperBand & SuccessiveHalving Evaluation Strategies<sup>[6]</sup><sup>[7]</sup> and MapReduce & Async Communication Conditions.
Finally, you can visualize Config Space and optimization process & results by UltraOpt's tool function. Enjoy it !
Other Language: 中文README
-
Documentation
-
English Documentation is not available now.
-
-
Tutorials
-
English Tutorials is not available now.
-
Table of Contents
Installation
UltraOpt requires Python 3.6 or higher.
You can install the latest release by pip:
pip install ultraopt
You can download the repository and manual installation:
git clone https://github.com/auto-flow/ultraopt.git && cd ultraopt
python setup.py install
Quick Start
Using UltraOpt in HPO
Let's learn what UltraOpt doing with several examples (you can try it on your Jupyter Notebook).
You can learn Basic-Tutorial in here, and HDL's Definition in here.
Before starting a black box optimization task, you need to provide two things:
- parameter domain, or the Config Space
- objective function, accept
config(configis sampled from Config Space), returnloss
Let's define a Random Forest's HPO Config Space by UltraOpt's HDL (Hyperparameter Description Language):
HDL = {
"n_estimators": {"_type": "int_quniform","_value": [10, 200, 10], "_default": 100},
"criterion": {"_type": "choice","_value": ["gini", "entropy"],"_default": "gini"},
"max_features": {"_type": "choice","_value": ["sqrt","log2"],"_default": "sqrt"},
"min_samples_split": {"_type": "int_uniform", "_value": [2, 20],"_default": 2},
"min_samples_leaf": {"_type": "int_uniform", "_value": [1, 20],"_default": 1},
"bootstrap": {"_type": "choice","_value": [True, False],"_default": True},
"random_state": 42
}
And then define an objective function:
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import cross_val_score, StratifiedKFold
from ultraopt.hdl import layering_config
X, y = load_digits(return_X_y=True)
cv = StratifiedKFold(5, True, 0)
def evaluate(config: dict) -> float:
model = RandomForestClassifier(**layering_config(config))
return 1 - float(cross_val_score(model, X, y, cv=cv).mean())
Now, we can start an optimization process:
from ultraopt import fmin
result = fmin(eval_func=evaluate, config_space=HDL, optimizer="ETPE", n_iterations=30)
result
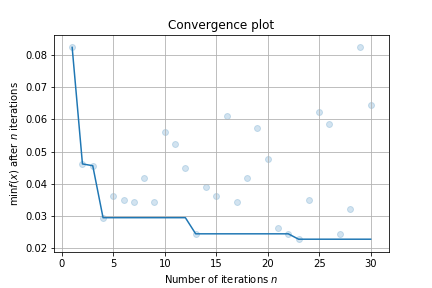
100%|██████████| 30/30 [00:36<00:00, 1.23s/trial, best loss: 0.023]
+-----------------------------------+
| HyperParameters | Optimal Value |
+-------------------+---------------+
| bootstrap | True:bool |
| criterion | gini |
| max_features | log2 |
| min_samples_leaf | 1 |
| min_samples_split | 2 |
| n_estimators | 200 |
+-------------------+---------------+
| Optimal Loss | 0.0228 |
+-------------------+---------------+
| Num Configs | 30 |
+-------------------+---------------+
Finally, make a simple visualizaiton:
result.plot_convergence()
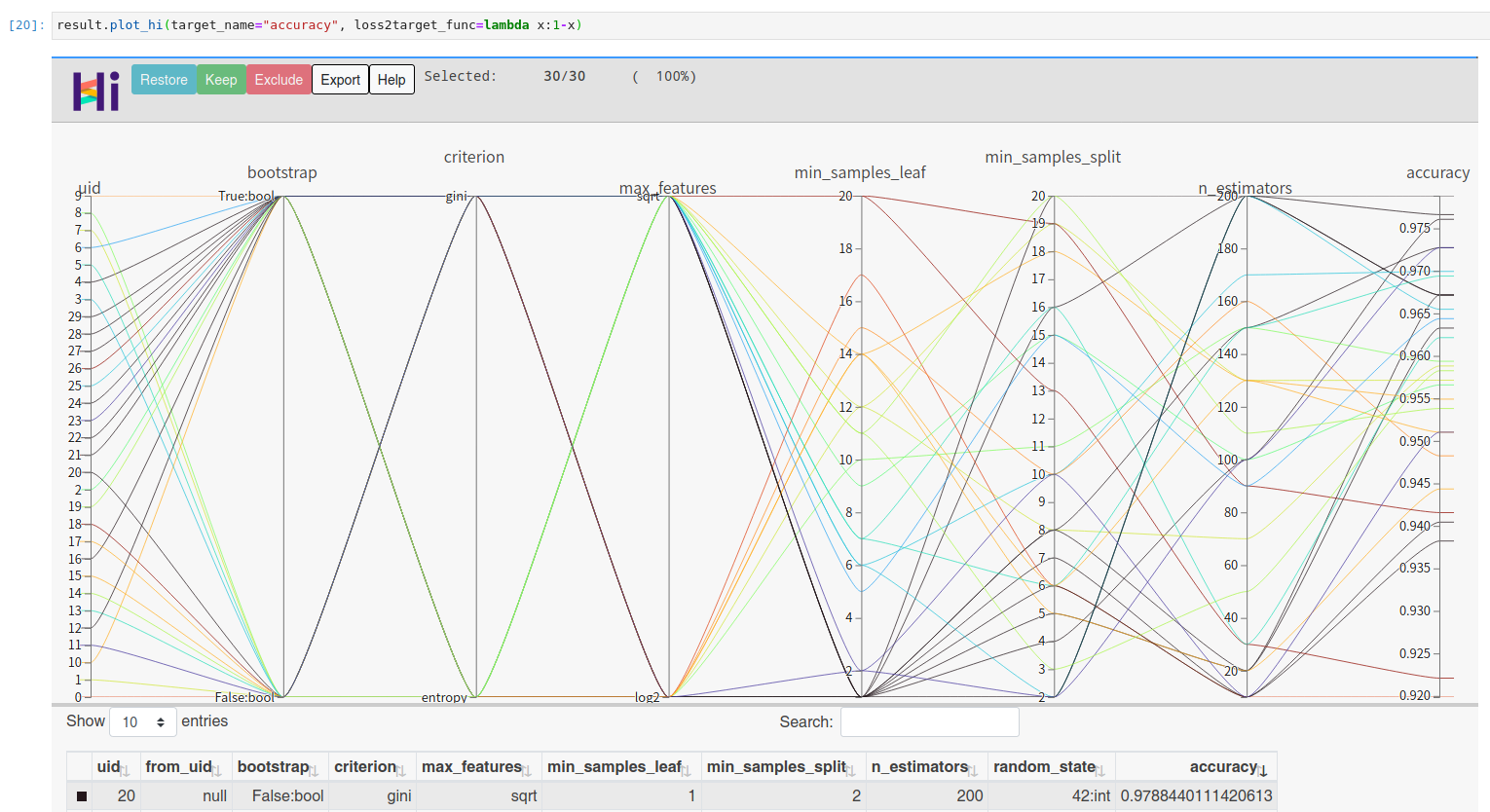
You can visualize high dimensional interaction by facebook's hiplot:
!pip install hiplot
result.plot_hi(target_name="accuracy", loss2target_func=lambda x:1-x)
Using UltraOpt in AutoML
Let's try a more complex example: solve AutoML's CASH Problem <sup>[1]</sup> (Combination problem of Algorithm Selection and Hyperparameter optimization)
by BOHB algorithm<sup>[2]</sup> (Combine HyperBand<sup>[6]</sup> Evaluation Strategies with UltraOpt's ETPE optimizer) .
You can learn Conditional Parameter and complex HDL's Definition in here, AutoML implementation tutorial in here and Multi-Fidelity Optimization in here.
First of all, let's define a CASH HDL :
HDL = {
'classifier(choice)':{
"RandomForestClassifier": {
"n_estimators": {"_type": "int_quniform","_value": [10, 200, 10], "_default": 100},
"criterion": {"_type": "choice","_value": ["gini", "entropy"],"_default": "gini"},
"max_features": {"_type": "choice","_value": ["sqrt","log2"],"_default": "sqrt"},
"min_samples_split": {"_type": "int_uniform", "_value": [2, 20],"_default": 2},
"min_samples_leaf": {"_type": "int_uniform", "_value": [1, 20],"_default": 1},
"bootstrap": {"_type": "choice","_value": [True, False],"_default": True},
"random_state": 42
},
"KNeighborsClassifier": {
"n_neighbors": {"_type": "int_loguniform", "_value": [1,100],"_default": 3},
"weights" : {"_type": "choice", "_value": ["uniform", "distance"],"_default": "uniform"},
"p": {"_type": "choice", "_value": [1, 2],"_default": 2},
},
}
}
And then, define a objective function with an additional parameter budget to adapt to HyperBand<sup>[6]</sup> evaluation strategy:
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
def evaluate(config: dict, budget: float) -> float:
layered_dict = layering_config(config)
AS_HP = layered_dict['classifier'].copy()
AS, HP = AS_HP.popitem()
ML_model = eval(AS)(**HP)
scores = []
for i, (train_ix, valid_ix) in enumerate(cv.split(X, y)):
rng = np.random.RandomState(i)
size = int(train_ix.size * budget)
train_ix = rng.choice(train_ix, size, replace=False)
X_train,y_train = X[train_ix, :],y[train_ix]
X_valid,y_valid = X[valid_ix, :],y[valid_ix]
ML_model.fit(X_train, y_train)
scores.append(ML_model.score(X_valid, y_valid))
score = np.mean(scores)
return 1 - score
You should instance a multi_fidelity_iter_generator object for the purpose of using HyperBand<sup>[6]</sup> Evaluation Strategy :
from ultraopt.multi_fidelity import HyperBandIterGenerator
hb = HyperBandIterGenerator(min_budget=1/4, max_budget=1, eta=2)
hb.get_table()
