Relearn
A Reinforcement Learning Library for C++11/14
Install / Use
/learn @alexge233/RelearnREADME

A Reinforcement Learning header-only template library for C++14. Minimal and simple to use, for a variety of scenarios. It is based on Sutton and Barto's book and implements some of the functionality described in it.
Currently the library implements Q-Learning for deterministic systems, as well as non-deterministic systems.
The Q-Learning (for both offline and online policy update rule) is:
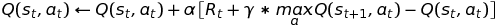
The policy decision is entirely up to you to decide; in the case of a deterministic system, usually the options are to either stay on policy:
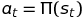
or if using online explorative-greedy (ε-Greedy) assign some decaying probability on using the policy or taking a random action:
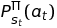
For Q-Learning in a non-deterministic system (e.g., when the certainty of transitioning from one state to another is not constant) we use a transition function:
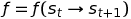
That transition function, suggests that from state s_t if taking action a_t the agent ends up in state s_{t+1}.
The assigned probability of that transition must be observed after being taken:
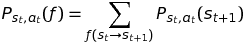
This probability quantifies the likelihood of the transition s_t → s_{t+1} for action a_t.
Similarly, the Expected reward is:
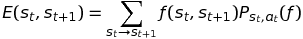
This simply states that the reward is equivalent to the reward of the ending-up state s_{t+1} affected by the transition probability.
Therefore, the update rule for probabilistic systems is:
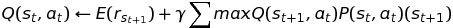
Implementation in C++
The template class policy allows the use of your own state and action classes,
although a pair of template wrapper classs state and action is provided in the header.
You can create your own state and action classes and use them, but they must satisfy the below criteria:
- terminal states must have a reward exposed by a method
::reward() - states and actions must be hashable
The classes state and action provided in the header wrap around your own state and action structures,
which can be anything, provided they are hashable.
Take care to make them unique, otherwise the result may be undefined behaviour.
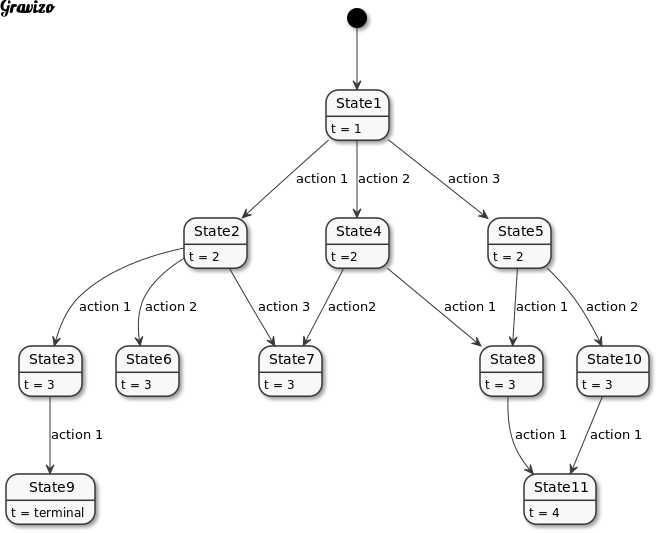
Markov Decision Process
An MDP is a sequence of States s<sub>t</sub> linked together by actions a<sub>t</sub>.
At the core of relearn is the policy which uses MDPs and maps them using the final state reward R.
Whilst multiple episodes may exist, and an episode may be iterated many times, updated, evaluated
and re-experienced, the actual process is done in class policy. An overview of an MDP is shown below.
The template parameters state_trait and action_trait are used to describe what a state and action are,
the wrappers are used only for indexing, hashing and policy calculation.
The basic use is to create episodes, denoted as markov_chain which you populate as you see fit,
and then reward with either a negative (-1), neutral (0) or positive (+1) value.
The use of a markov_chain defaults to an std::deque<relearn::link<state_class,action_class>>
where relearn::link is the struct encapsulating a state/action observation.
You may replace the container or link class if you want, but the q_learning structure
requires that:
- an episode (a
markov_chain) can be iterated - there exists an
::size()method to denote the size of the episode
Basically most STL containers should work right out of the box.
The library uses by default double for storing and updating Q values,
but you can play around with it if needed.
The class that mostly interests us is policy which uses your states and action,
and stores them in a map of states, where each state (key) has a value of maps (action to value):
.
├── s_t
| ├── a_t: 0.03
| └── a_t: -0.05
├── s_t
| ├── a_t: -0.001
| └── a_t: 0.9
You own and control the policy objects, and you can even use multiple ones, however bear in mind
that they are not locked for MT access (you have to do this manually).
Using q_learning you can then set/update the policy values by iterating your episodes.
Dependencies
There are no external dependencies! However, your compiler must support C++14, so you will need:
- gcc 4.8.4 or higher
- clang 3.3 or higher
note: I haven't tested with a Windows platform!
note: If you need serialization, current master branch has a flag USING_BOOST_SERIALIZATION,
which when set to ON will enable boost serialization, provided that your states and actions (template parameters state_trait and action_trait are indeed serializable).
In this case, you need to use CMake's find_package to properly find, include and link against boost_serialization.
Building
There is nothing to build! This is a header-only library, you only need to use the relearn.hpp header. However, you may compile the examples in order to see how the library is implemented.
To do that, simply:
mkdir build
cd build
cmake ..
make
build examples
Simply do the following:
cmake .. -DBUILD_EXAMPLES=On
make
build tests
cmake .. -DBUILD_TESTS=On
enable serialization
In order to enable serialization, you need boost and boost-serialization. See your distro on how to install those. To enable it, pass a cmake flag:
cmake .. -DUSING_BOOST_SERIALIZATION=On
For example if you want to run the tests with serialization:
cmake .. -DUSING_BOOST_SERIALIZATION=On -DBUILD_EXAMPLES=On
You can also set this flag for your own project, if you wish to save and load
policies, states or actions.
Do bear in mind that the state_trait (e.g., your state descriptor) and the
action_trait (e.g., your action descriptor) must also be serializable.
On how to achieve this, have a look at this tutorial
if this condition is not met, you will end up with compilation errors.
Because of the flexibility of boost serialization, you can save and load binary, text or xml archives.
Later versions of boost support smart pointers, so even if your descriptors are
std::shared_ptr or std::unique_ptr you can still save and load them.
Examples
There is a folder examples which I'm populating with examples, starting from your typical gridworld problem,
and then moving on to a blackjack program.
Currently there are two "Gridworld" examples:
- an offline on-policy algorithm:
examples/gridworld_offline.cppbuilt asex_gridworld_offline - an online on-policy algorithm:
examples/gridworld_online.cppbuilt asex_gridworld_online
basic usage
The basic way of using the library is the following:
- create a class state, or use an existing class, structure, or PDT which describes (in a Markovian sense) your state
- create a class action, or use an existing class, structure, or PDT which describes the action.
- create an episode which by default is an
std::deque<relearn::link<state,action>>which you populate, and then reward.
At this point, depending on wether you are using an online or offline algorith/approach, you have the following options:
- keep creating episodes, obtain a reward for the last/terminal state, and once you have finished, train the policy will all of them, or
- every time you create an episode, obtain the reward, then you can train your policy with it.
That choice is up to you, and almost always depends on the domain, system or problem you're trying to solve.
It is for this reason that there is no implementation of on_policy or off_policy or e_greedy,
those are very simple algorithms, and are application-specific.
Take a look at the gridworld examples, which demonstrate two different ways of achieving the same task.
The blackjack example is different: because playing Blackjack is a probability task, we can't use
a deterministic approach, rather we use a probabilistic approach, in which case
- we have to take an offline approach (we don't know the transition from one state to another until we've experienced it)
- we have to train on probabilities of transitioning (e.g., non-deterministic)
Gridworld

The pinacle of simplicity when it comes to block/grid world toy problems, our agent resides in a 10x10 gridworld, which is surrounded by blocks into which he can't move (black colour). The agent starts at blue (x:1,y:8) and the target is the green (x:1,y:1). The red blocks are fire/danger/a negative reward, and there is a rudimentary maze.
There are two versions of the Gridworld, the offline approach:
- first the agent randomly explores until it can find the positive reward (+1.0) grid block
- then it updates its policies
- finally it follows the best policy learnt
And the online approach:
- the agent randomly explores one episode
Related Skills
YC-Killer
2.7kA library of enterprise-grade AI agents designed to democratize artificial intelligence and provide free, open-source alternatives to overvalued Y Combinator startups. If you are excited about democratizing AI access & AI agents, please star ⭐️ this repository and use the link in the readme to join our open source AI research team.
best-practices-researcher
The most comprehensive Claude Code skills registry | Web Search: https://skills-registry-web.vercel.app
groundhog
399Groundhog's primary purpose is to teach people how Cursor and all these other coding agents work under the hood. If you understand how these coding assistants work from first principles, then you can drive these tools harder (or perhaps make your own!).
workshop-rules
Materials used to teach the summer camp <Data Science for Kids>
