VIEScore
Visual Instruction-guided Explainable Metric. Code for "Towards Explainable Metrics for Conditional Image Synthesis Evaluation" (ACL 2024)
Install / Use
/learn @TIGER-AI-Lab/VIEScoreREADME
VIEScore
![]()



![]()
This repository hosts the code and data of our ACL 2024 Paper VIEScore: Towards Explainable Metrics for Conditional Image Synthesis Evaluation.
VIEScore is a Visual Instruction-guided Explainable metric for evaluating any conditional image generation tasks.
<div align="center"> 🔥 🔥 🔥 Check out our <a href = "https://tiger-ai-lab.github.io/VIEScore/">[Project Page and Leaderboard]</a> for more results and analysis! </div> <div align="center"> <img src="https://github.com/TIGER-AI-Lab/VIEScore/blob/gh-pages/static/images/teaser.png" width="100%"> Metrics in the future would provide the score and the rationale, enabling the understanding of each judgment. Which method (VIEScore or traditional metrics) is “closer” to the human perspective? </div>📰 News
- 2024 Jun 17: We released the standalone version of VIEScore.
- 2024 May 23: We released all the results and notebook to visualize the results.
- 2024 May 23: Added Gemini-1.5-pro results.
- 2024 May 16: Added GPT4o results and we found that GPT4o achieve on par correlation with human across all tasks!
- 2024 May 15: VIEScore is accepted to ACL2024 (main)!
- 2024 Jan 11: Code is released!
- 2023 Dec 24: Paper available on Arxiv. Code coming Soon!
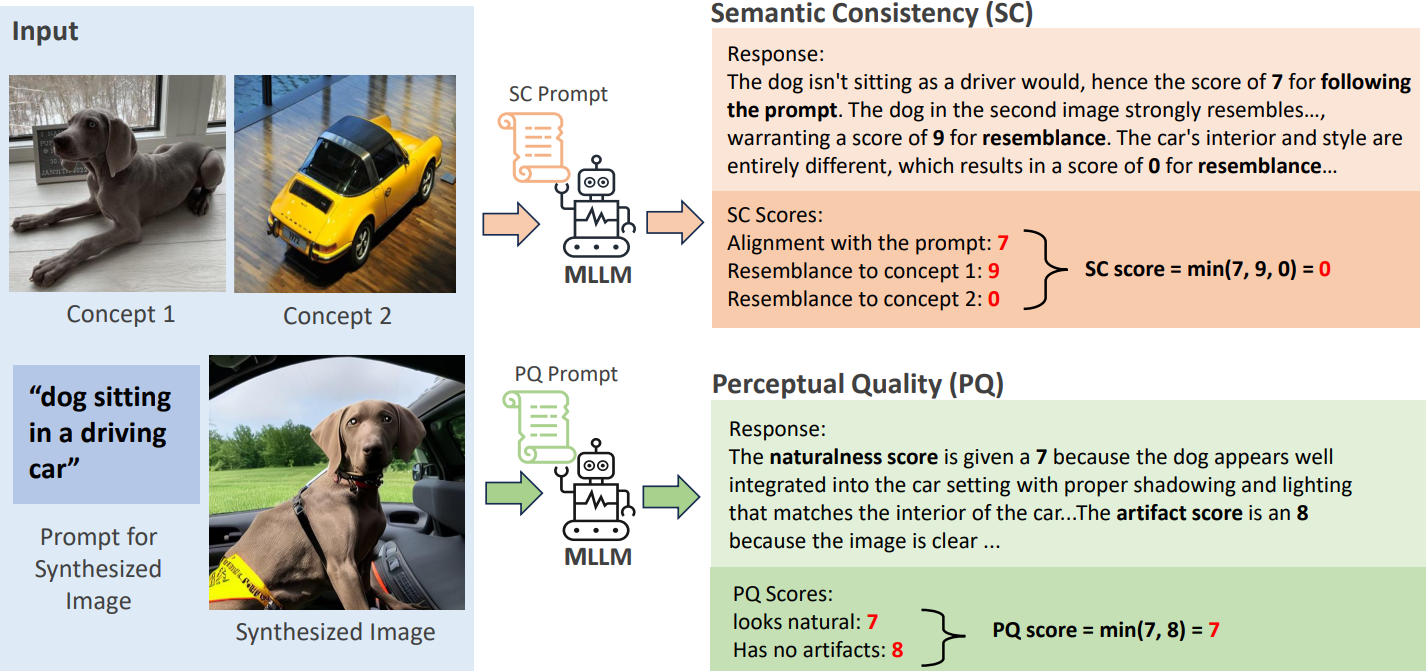
VIEScore gives an SC(semantic consistency score), PQ(perceptual quality score), and O (Overall score) to evaluate your image/video.
Paper implementation
See https://github.com/TIGER-AI-Lab/VIEScore/tree/main/paper_implementation
$ python3 run.py --help
usage: run.py [-h] [--task {tie,mie,t2i,cig,sdig,msdig,sdie}] [--mllm {gpt4v, gpt4o, llava,blip2,fuyu,qwenvl,cogvlm,instructblip,openflamingo, gemini}] [--setting {0shot,1shot}] [--context_file CONTEXT_FILE]
[--guess_if_cannot_parse]
Run different task on VIEScore.
optional arguments:
-h, --help show this help message and exit
--task {tie,mie,t2i,cig,sdig,msdig,sdie}
Select the task to run
--mllm {gpt4v, gpt4o, llava,blip2,fuyu,qwenvl,cogvlm,instructblip,openflamingo, gemini}
Select the MLLM model to use
--setting {0shot,1shot}
Select the incontext learning setting
--context_file CONTEXT_FILE
Which context file to use.
--guess_if_cannot_parse
Guess a value if the output cannot be parsed.
Standard Version (For Development and Extension)
See https://github.com/TIGER-AI-Lab/VIEScore/tree/main/viescore
from viescore import VIEScore
backbone = "gemini"
vie_score = VIEScore(backbone=backbone, task="t2v")
score_list = vie_score.evaluate(pil_image, text_prompt)
sementics_score, quality_score, overall_score = score_list
Paper Results
<div align="center"> <img src="https://tiger-ai-lab.github.io/VIEScore/static/images/table_overall_new.png" width="50%"> </div>Citation
Please kindly cite our paper if you use our code, data, models or results:
@misc{ku2023viescore,
title={VIEScore: Towards Explainable Metrics for Conditional Image Synthesis Evaluation},
author={Max Ku and Dongfu Jiang and Cong Wei and Xiang Yue and Wenhu Chen},
year={2023},
eprint={2312.14867},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Related Skills
qqbot-channel
347.0kQQ 频道管理技能。查询频道列表、子频道、成员、发帖、公告、日程等操作。使用 qqbot_channel_api 工具代理 QQ 开放平台 HTTP 接口,自动处理 Token 鉴权。当用户需要查看频道、管理子频道、查询成员、发布帖子/公告/日程时使用。
docs-writer
100.1k`docs-writer` skill instructions As an expert technical writer and editor for the Gemini CLI project, you produce accurate, clear, and consistent documentation. When asked to write, edit, or revie
model-usage
347.0kUse CodexBar CLI local cost usage to summarize per-model usage for Codex or Claude, including the current (most recent) model or a full model breakdown. Trigger when asked for model-level usage/cost data from codexbar, or when you need a scriptable per-model summary from codexbar cost JSON.
Design
Campus Second-Hand Trading Platform \- General Design Document (v5.0 \- React Architecture \- Complete Final Version)1\. System Overall Design 1.1. Project Overview This project aims t
