DevRadar
No description available
Install / Use
/learn @Pirat102/DevRadarREADME
DevRadar
A centralized platform for IT job seekers in Poland, aggregating listings from multiple job boards.
Live: https://devradar.work
Youtube Preview
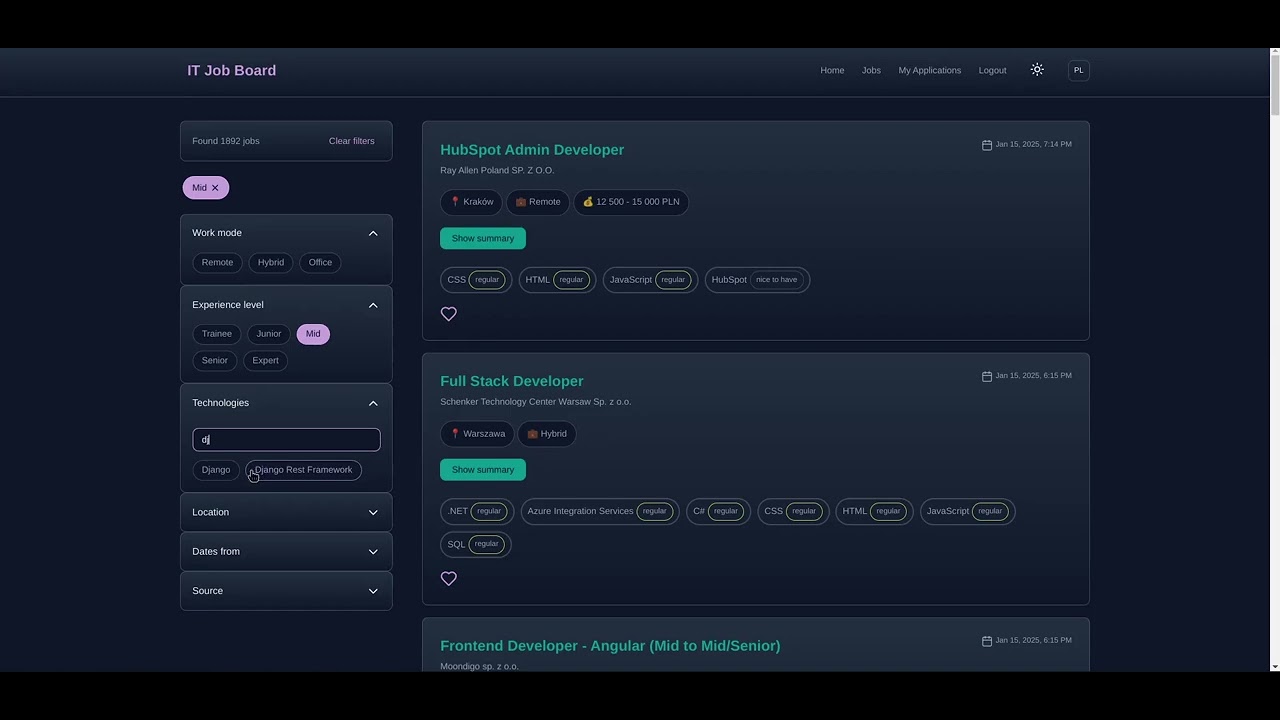
🚀 Features
- 🔍 Real-time job aggregation from major Polish job boards:
- Pracuj.pl
- NoFluffJobs
- JustJoinIT
- TheProtocol
- 📊 Interactive market statistics dashboard
- 🤖 AI-powered job description summarization using ChatGPT
- 👤 Personal job application tracking system
- 🌐 Bilingual interface (Polish/English)
- 🎯 Advanced filtering system
- 🌙 Light/Dark theme
- 📱 Responsive design
- ⚡ Optimized performance through React, Redis caching, and database indexing
🎯 Overview
DevRadar helps IT job seekers save time by:
- Providing quick access to key job details (skills, location, salary, work mode) without extra clicks
- Offering AI-powered summaries of job descriptions
- Enabling easy application tracking with notes and status updates
- Maintaining historical job market data for trends analysis

Application Tracking
Track your job applications with status updates, notes, and automatic date management.

Interactive Dashboard
Track current market trends.

Techstack
Backend
- 🐍 Django + 🛡️ Django Ninja (REST API)
- 📄 BeautifulSoup4 (Web scraping)
- ⏰ Celery (Periodic task execution for web scraping)
- 🤖 ChatGPT API (Summarizing descriptions)
Database
- 🐘 PostgreSQL
- 🗄️ Redis (Caching and Celery broker)
DevOps
- 🐳 Docker (Containerization)
- 🌐 Hetzner (VPS)
- 📡 Nginx (Reverse proxy)
Frontend
- ⚡ Vite + ⚛️ React
Distinctiveness and Complexity
This project stands out for several key reasons:
-
Advanced Web Scraping System
- Implements a robust scraping architecture with base and specialized scrapers
- Handles multiple data sources with different structures
- Includes automatic rate limiting and error handling
- Uses BeautifulSoup4 for parsing with specialized selectors for each source
-
Sophisticated Data Processing
- Implements salary standardization across different formats
- Uses AI (ChatGPT) for intelligent job description summarization
- Maintains data history while preventing duplicate entries
- Features complex filtering and search capabilities
-
Performance Optimizations
- Redis caching for frequently accessed data
- Database indexing for efficient queries
- Celery for background task processing
- Docker containerization for scalability
-
Complex Frontend Architecture
- Custom hooks for state management
- Bilingual support with context-based translations
- Theme switching capability
- Responsive design with mobile-first approach
Directory Structure
Root (DevRadar)
docker-compose.prod.yml: Docker main setup for productiondocker-compose.yml: Docker main setup for development
Backend (/backend)
Core Files
backend/settings.py: Main Django configurationbackend/celery.py: Celery configuration for background tasksbackend/urls.py: Main URL routingbackend/Dockerfile: Development Dockerfilebackend/Dockerfile.prod: Production Dockerfile
Jobs App
jobs/api.py: API endpoints using Django Ninjajobs/models.py: Database models for jobs and applicationsjobs/schemas.py: Schemas used by Django Ninja for API endpointsjobs/summarizer.py: ChatGPT integrationjobs/tasks.py: Celery task for running Django commandjobs/management/commands/run_scrapers.py: Django command for running scrapersjobs/management/commands/: Depricated commands, used for cleaning and standardizing datajobs/scrapers/: Web scraping implementationbase_scraper.py: Base scraper classjustjoin_scraper.py: JustJoinIT specific scrapernofluffjobs.py: NoFluffJobs specific scraperpracuj_scraper.py: Pracuj.pl specific scraperprotocol_scraper.py: TheProtocol specific scraper
jobs/utils/: Utility functionssalary_standardizer.py: Salary format standardization
jobs/logs/: Log files
Frontend (/frontend)
src/components/: React componentssrc/hooks/: Custom React hookssrc/styles/: CSS stylessrc/contexts/: React contextssrc/config/: Configuration filesDockerfile: Development DockerfileDockerfile.prod: Production Dockerfile
Installation
Prerequisites
- Docker and Docker Compose
- Git
Environment Setup
- Clone the repository:
git clone https://github.com/Pirat102/DevRadar.git
cd DevRadar
- Set up backend environment:
cp backend/.env.example backend/.env
Edit backend/.env
- Set up frontend environment:
cp frontend/.env.example frontend/.env
Running the Application
- Build and start containers:
docker compose up --build -d
- Create database migrations:
docker compose exec django python manage.py makemigrations
docker compose exec django python manage.py migrate
- Rebuild containers:
docker compose up --build -d
The application will be available at:
- Frontend: http://localhost:5173
- Backend API: http://localhost:8000
- API Documentation: http://localhost:8000/api/docs
- Flower (Celery monitoring): http://localhost:5555
Additional Information
Data Updates
- Job listings are updated every 1 hours via Celery tasks
- Salary data is automatically standardized to monthly PLN format
Performance
- Redis caching is used for frequently accessed data (filters, statistics)
- Database queries are optimized with appropriate indexes
Development Notes
- API documentation is available at
/api/docs - Celery monitoring is available through Flower interface
- The application uses ChatGPT API for job description summarization
Related Skills
node-connect
347.2kDiagnose OpenClaw node connection and pairing failures for Android, iOS, and macOS companion apps
frontend-design
108.0kCreate distinctive, production-grade frontend interfaces with high design quality. Use this skill when the user asks to build web components, pages, or applications. Generates creative, polished code that avoids generic AI aesthetics.
openai-whisper-api
347.2kTranscribe audio via OpenAI Audio Transcriptions API (Whisper).
qqbot-media
347.2kQQBot 富媒体收发能力。使用 <qqmedia> 标签,系统根据文件扩展名自动识别类型(图片/语音/视频/文件)。
