PyVHDLParser
Streaming based VHDL parser.
Install / Use
/learn @Paebbels/PyVHDLParserREADME
![]()














pyVHDLParser
This is a token-stream based parser for VHDL-2008.
This project requires Python 3.8+.
Introduction
Main Goals
- Parsing
- slice an input document into tokens and text blocks which are categorized
- preserve case, whitespace and comments
- recover on parsing errors
- good error reporting / throw exceptions
- Fast Processing
- multi-pass parsing and analysis
- delay analysis if not needed at current pass
- link tokens and blocks for fast-forward scanning
- Generic VHDL Language Model
- Assemble a document-object-model (Code-DOM)
- Provide an API for code introspection
Use Cases
- generate documentation by using the fast-forward scanner
- generate a document/language model by using the grouped text-block scanner
- extract compile orders and other dependency graphs
- generate highlighted syntax
- re-annotate documenting comments to their objects for doc extraction
Parsing approach
- slice an input document into tokens
- assemble tokens to text blocks which are categorized
- assemble text blocks for fast-forward scanning into groups
- translate groups into a document-object-model (DOM)
- provide a generic VHDL language model
Long time goals
-
A Sphinx language plugin for VHDL
TODO: Move the following documentation to ReadTheDocs and replace it with a more lightweight version.
Basic Concept
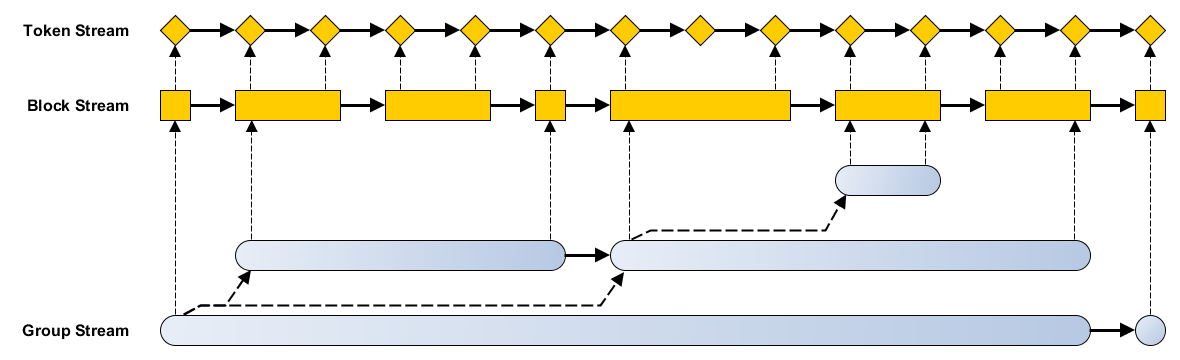
Example 1
This is an input file:
-- Copryright 2016
library IEEE;
use IEEE.std_logic_1164.all;
entity myEntity is
generic (
BITS : positive := 8
);
port (
Clock : in std_logic;
Output : out std_logic_vector(BITS - 1 downto 0)
);
end entity;
architecture rtl of myEntity is
constant const0 : integer := 5;
begin
process(Clock)
begin
end process;
end architecture;
library IEEE, PoC;
use PoC.Utils.all, PoC.Common.all;
package pkg0 is
function func0(a : integer) return string;
end package;
package body Components is
function func0(a : integer) return string is
procedure proc0 is
begin
end procedure;
begin
end function
end package body;
Step 1
The input file (stream of characters) is translated into stream of basic tokens:
StartOfDocumentTokenLinebreakTokenSpaceTokenIndentationToken
WordTokenCharacterTokenFusedCharacterToken
- CommentToken
SingleLineCommentTokenMultiLineCommentToken
EndOfDocumentToken
The stream looks like this:
<StartOfDocumentToken>
<SLCommentToken '-- Copryright 2016\n' ................ at 1:1>
<WordToken 'library' ............................. at 2:1>
<SpaceToken ' ' ................................... at 2:8>
<WordToken 'IEEE' ................................ at 2:9>
<CharacterToken ';' ................................... at 2:13>
<LinebreakToken ---------------------------------------- at 2:14>
<WordToken 'use' ................................. at 3:1>
<SpaceToken ' ' ............................... at 3:4>
<WordToken 'IEEE' ................................ at 3:9>
<CharacterToken '.' ................................... at 3:13>
<WordToken 'std_logic_1164' ...................... at 3:14>
<CharacterToken '.' ................................... at 3:28>
<WordToken 'all' ................................. at 3:29>
<CharacterToken ';' ................................... at 3:32>
<LinebreakToken ---------------------------------------- at 3:33>
<LinebreakToken ---------------------------------------- at 4:1>
<WordToken 'entity' .............................. at 5:1>
<SpaceToken ' ' ................................... at 5:7>
<WordToken 'myEntity' ............................ at 5:8>
<SpaceToken ' ' ................................... at 5:16>
<WordToken 'is' .................................. at 5:17>
<LinebreakToken ---------------------------------------- at 5:19>
<IndentToken '\t' .................................. at 6:1>
<WordToken 'generic' ............................. at 6:2>
<SpaceToken ' ' ................................... at 6:9>
<CharacterToken '(' ................................... at 6:10>
<LinebreakToken ---------------------------------------- at 6:11>
<IndentToken '\t\t' ................................ at 7:1>
<WordToken 'BITS' ................................ at 7:3>
<SpaceToken ' ' ................................... at 7:7>
<CharacterToken ':' ................................... at 7:8>
<SpaceToken ' ' ................................... at 7:8>
<WordToken 'positive' ............................ at 7:10>
<SpaceToken ' ' ................................... at 7:18>
<FusedCharToken ':=' .................................. at 7:19>
<SpaceToken ' ' ................................... at 7:21>
<WordToken '8' ................................... at 7:22>
<LinebreakToken ---------------------------------------- at 7:23>
<IndentToken '\t' .................................. at 8:1>
<CharacterToken ')' ................................... at 8:2>
<CharacterToken ';' ................................... at 8:3>
<LinebreakToken ---------------------------------------- at 8:4>
<IndentToken '\t' .................................. at 9:1>
<WordToken 'port' ................................ at 9:2>
<SpaceToken ' ' ................................... at 9:6>
<CharacterToken '(' ................................... at 9:7>
<LinebreakToken ---------------------------------------- at 9:8>
<IndentToken '\t\t' ................................ at 10:1>
<WordToken 'Clock' ............................... at 10:3>
<SpaceToken ' ' ................................. at 10:8>
<CharacterToken ':' ................................... at 10:11>
<SpaceToken ' ' ................................... at 10:11>
<WordToken 'in' .................................. at 10:13>
<SpaceToken ' ' .................................. at 10:15>
<WordToken 'std_logic' ........................... at 10:17>
<CharacterToken ';' ................................... at 10:26>
<LinebreakToken ---------------------------------------- at 10:27>
<IndentToken '\t\t' ................................ at 11:1>
<WordToken 'Output' .............................. at 11:3>
<SpaceToken ' ' ................................... at 11:9>
<CharacterToken ':' ................................... at 11:10>
<SpaceToken ' ' ................................... at 11:10>
<WordToken 'out' ................................. at 11:12>
<SpaceToken ' ' ................................... at 11:15>
<WordToken 'std_logic_vector' .................... at 11:16>
<CharacterToken '(' ................................... at 11:32>
<WordToken 'BITS' ................................ at 11:33>
<SpaceToken ' ' ................................... at 11:37>
<CharacterToken '-' ................................... at 11:38>
<SpaceToken ' ' ................................... at 11:38>
<WordToken '1' ................................... at 11:40>
<SpaceToken ' ' ................................... at 11:41>
<WordToken 'downto' .............................. at 11:42>
<SpaceToken ' ' ................................... at 11:48>
<WordT
