SeqFM
A pytorch implementation of SeqFM(Sequence-Aware Factorization Machines for Temporal Predictive Analytics.) [ICDE20]
Install / Use
/learn @MogicianXD/SeqFMREADME
SeqFM
A pytorch implementation of SeqFM:
Chen Tong, Yin Hongzhi, Hung Nguyen, Peng Wen-Chih, Li Xue, Zhou Xiaofang. (2020). Sequence-Aware Factorization Machines for Temporal Predictive Analytics. In ICDE'20, 2020
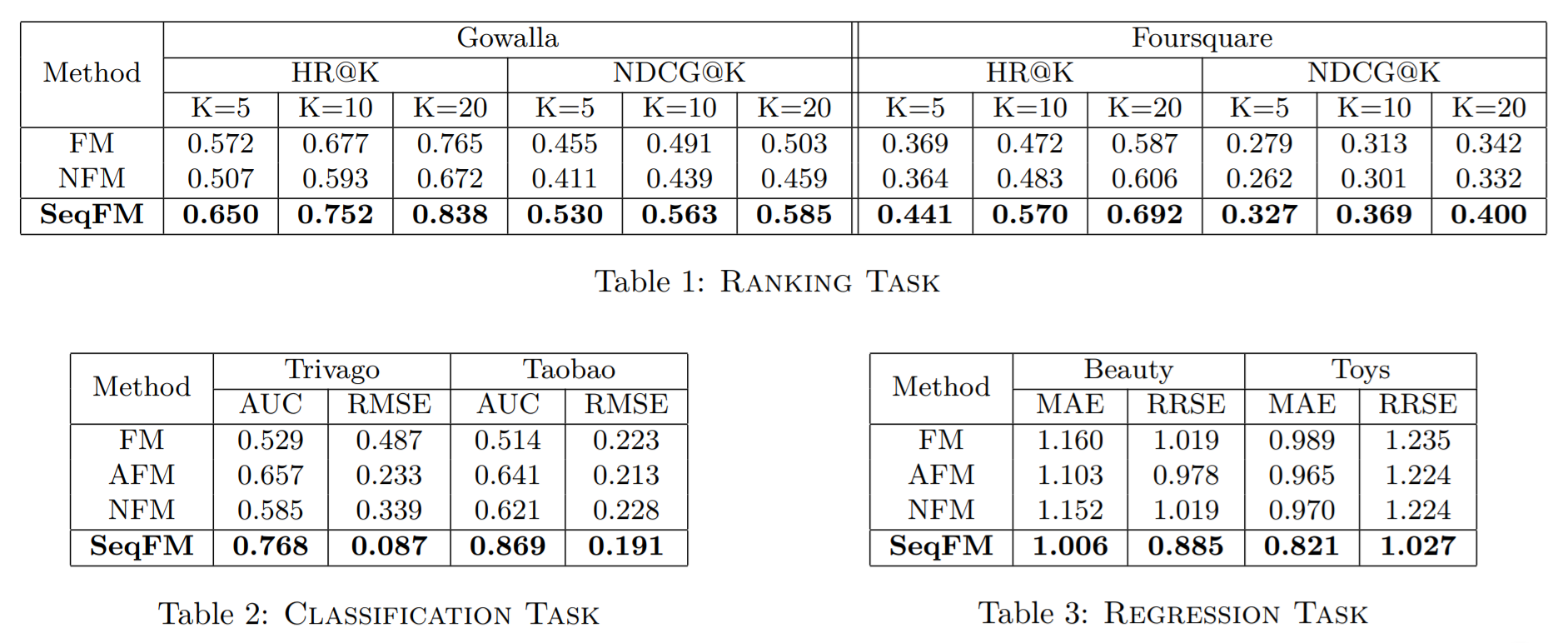
Performance Comparison
Files in the folder
src/BaseModel.py: The base class encapsulates device initialization, train & test tasks for rank, classification and regression.layer.py: Provides masked softmax function andSelfAttentionlayer along withMultiHeadSelfAttentiondataset.py: Derived fromtorch.util.data.DatasetStaticDynamicDataset: Dataset for rank and classification with negative sampling.StaticDynamicRatingDataset: Dataset for regression with numerical value per sample.
util.py: ProvidesBPRloss functions,MRRandNDCGfunctions, and other functions.SeqFM.py:ResFNN: The residual forward-feeding network specially modified in this model.SeqFM: The core model.
SeqFM_gru.py: A Variant using a gru instead of mean pooling.
main.py: You can look for descriptions of args with-hpreprocess_neg.py: export data with negative sampling.preprocess_rate.py: export data without negative sampling, but with ratings.../benchmarks/datasets/
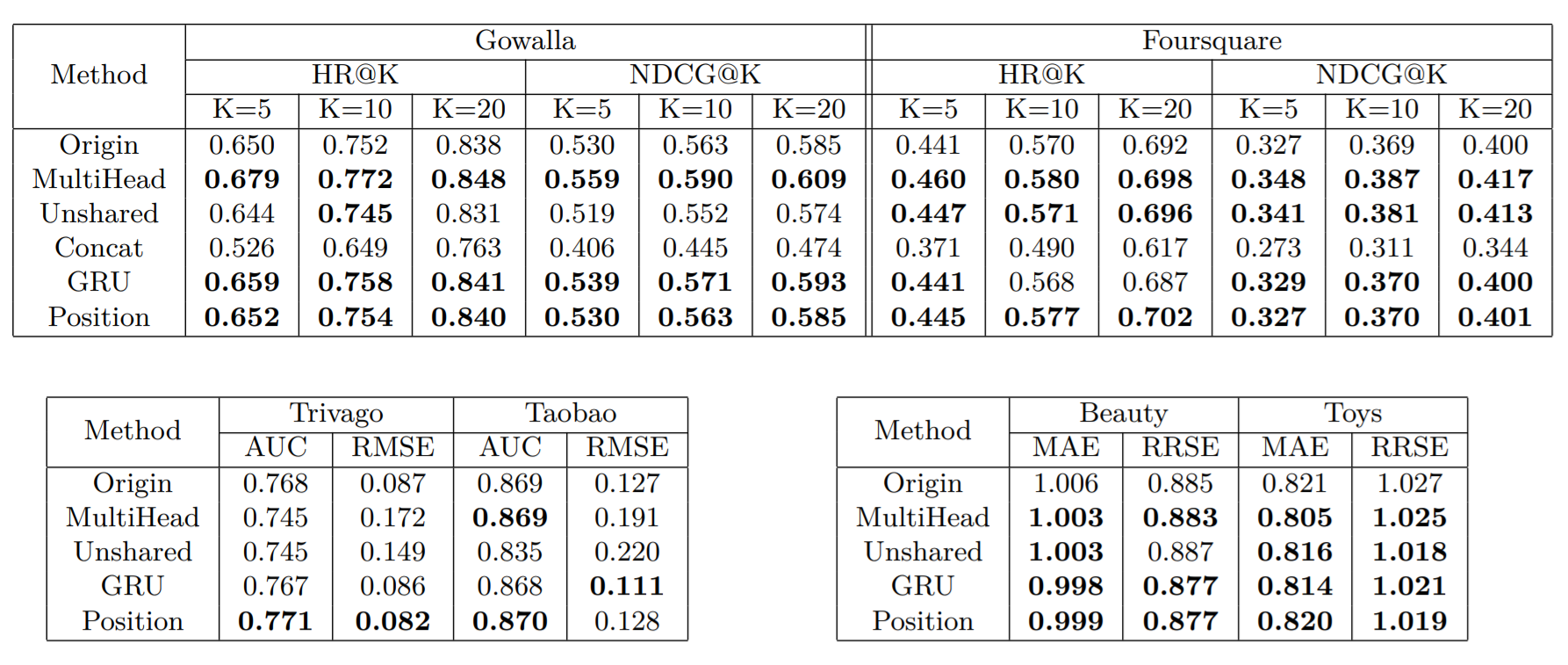
Variants
I designed several variants as following:
MultiHead:Use multi-head attention layer instead of a single attention layer.- For over half datasets, especially regression task, it achieved significant improvement.
- This variant increases time complexity, and it is not recommended as FM requires high speed.
Unshared:Each view owns a private FNN- For over half datasets, especially ranking task, it achieved significant improvement.
- This variant adds few parameters to learn but keeps time complexity, and it is recommended.
Concat:Concatenate static view and dynamic view as the input of FNN, with cross view dropped.- Bad performance. Deprecated.
GRU:For dynamic view, use GRU instead of simple average pooling,to emphasize temporal order.- A little improvement on rank tasks. An obvious improvement on regression tasks.
- It is worth using gru, when max length (20) is small. In case of vanishing gradient,position embedding is more suitable.
Position:Referring to transformer,add position embedding.- Just a little improvement on rank and regression. Position embedding is perhaps not learning enough.
Related Skills
feishu-drive
340.5k|
things-mac
340.5kManage Things 3 via the `things` CLI on macOS (add/update projects+todos via URL scheme; read/search/list from the local Things database)
clawhub
340.5kUse the ClawHub CLI to search, install, update, and publish agent skills from clawhub.com
postkit
PostgreSQL-native identity, configuration, metering, and job queues. SQL functions that work with any language or driver
