ImBD
[AAAI 2025 oral] Official repository of Imitate Before Detect: Aligning Machine Stylistic Preference for Machine-Revised Text Detection
Install / Use
/learn @Jiaqi-Chen-00/ImBDREADME
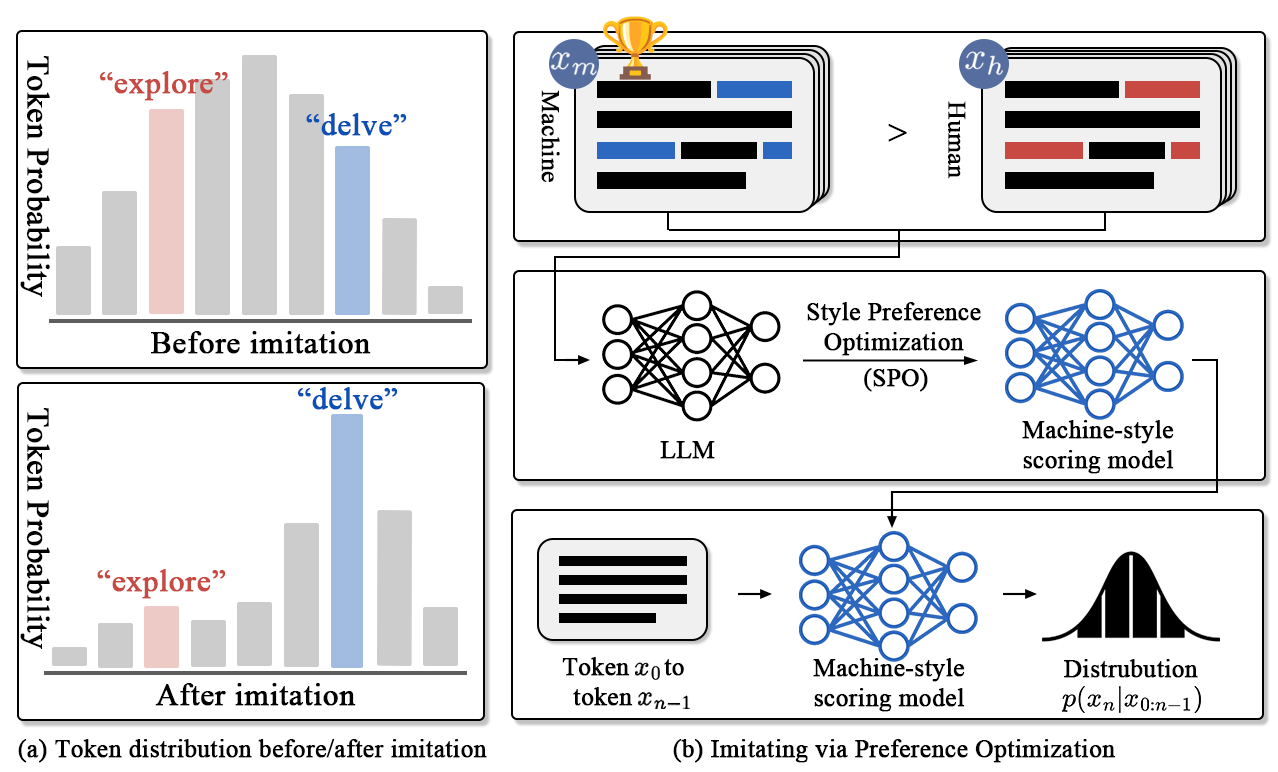
Detecting machine-revised text remains a challenging task as it often involves subtle style changes embedded within human-originated content. The ImBD framework introduces a novel approach to tackle this problem, leveraging style preference optimization (SPO) and Style-CPC to effectively capture machine-style phrasing. Our method achieves state-of-the-art performance in detecting revisions by open-source and proprietary LLMs like GPT-3.5 and GPT-4o, demonstrating significant efficiency with minimal training data.
We are excited to share our code and data to support further exploration in detecting machine-revised text. We welcome your feedback and invite collaborations to advance this field together!
🔥 News
- [2024, Dec 16] Our online demo is available on hugging-face now!
- [2024, Dec 13] Our model and local inference code are available!
- [2024, Dec 9] 🎉🎉 Our paper has been accepted by AAAI 25!
- [2024, Dec 7] We've released our website!
🛠️ Setup
Environment setup
conda create -n ImBD python=3.10
conda activate ImBD
pip install -r requirements.txt
Download necessary models to ./models
bash scripts/download_model.sh
🤖 Local Demo
[GPU memories needed for inference: ~11G]
We provide a script to download our inference checkpoint from huggingface. (Make sure you have download the above model since our inference checkpoint only contains lora weights)
bash scripts/download_inference_checkpoint.sh
You can also finetune and save the model from scratch according to our Reproduce Results part.
Next, run the following script to launch the demo:
bash scripts/run_inference.sh
There are two args in this script:
--task could be one of ["polish", "generate", "rewrite", "expand", "all"] . all denotes all-in-one combining the above four tasks, whose accuracy may not be as high as for a single task
--detail could be True or False, indicating whether to show the results of the four tasks.
🚀 Reproduce Results <a id="reproduce"></a>
Fast evaluation
[GPU memories needed for fast evaluation: ~11G]
bash scripts/eval_all.sh
The results will be saved at
./evaluationfolder. Make sure you have downloaded the inference checkpoint throughdownload_inference_checkpoint.sh
Reproduce Our Multi-domain Results
[GPU memories needed for training and evaluation: ~40G]
Tuning the gpt-neo-2.7b model with SPO (recommend)
bash scripts/train_spo.sh
Or download our full checkpoint without tuning again.
bash scripts/download_full_checkpoint.sh
Eval tuned model on our multi-domain datasets
# For polish task
bash scripts/eval_spo_polish.sh
# For rewrite task
bash scripts/eval_spo_rewrite.sh
# For expand task
bash scripts/eval_spo_expand.sh
# For generation task
bash scripts/eval_spo_generation.sh
Reproduce Our Multilang Results
The following script will train the model of corresponding language and automatically evaluate the model's result, including Spanish, Portuguese and Chinese.
bash scripts/train_spo_multilang.sh
Reproduce Other Methods' Results
First Download other models
bash scripts/download_other_models.sh
Then Eval other models on our datasets
# For polish task
bash scripts/eval_other_models_polish.sh
# For rewrite task
bash scripts/eval_other_models_rewrite.sh
# For expand task
bash scripts/eval_other_models_expand.sh
# For generation task
bash scripts/eval_other_models_generation.sh
Eval Roberta models on our datasets
# For four tasks
bash eval_supervised.sh
Train and eval sft/rlhf/orpo models on our datasets
# SFT
python ablation_exp/train_gpt_neo_sft.py
# RLHF
python ablation_exp/train_gpt_neo_rlhf.py
# ORPO
python ablation_exp/train_gpt_neo_orpo.py
# Eval
bash scripts/eval_ablation.sh
📁 Regenerate Data
For Opensource Model
Download text-generation models
Notes: You need to first apply for corresponding model download permission and fill the HF_TOKEN= in the download script, then remove the comments if you need to regenerate the datasets
bash scripts/download_other_models.sh
Build Data using opensource models
bash scripts/build_data.sh
For GPTs
We provide related codes in tools/data_builder_gpts. Make sure you fill the api_key and set the right path to save results.
✅ TODO
- [x] Inference code for detection.
- [ ] Optimize the preservation of the trained model.
- [x] LoRA checkpoint for inference and evaluation (without loading two full model checkpoint)
- [x] Optimize GPU memory usage for evaluation scripts.
Related Skills
qqbot-channel
347.9kQQ 频道管理技能。查询频道列表、子频道、成员、发帖、公告、日程等操作。使用 qqbot_channel_api 工具代理 QQ 开放平台 HTTP 接口,自动处理 Token 鉴权。当用户需要查看频道、管理子频道、查询成员、发布帖子/公告/日程时使用。
docs-writer
100.2k`docs-writer` skill instructions As an expert technical writer and editor for the Gemini CLI project, you produce accurate, clear, and consistent documentation. When asked to write, edit, or revie
model-usage
347.9kUse CodexBar CLI local cost usage to summarize per-model usage for Codex or Claude, including the current (most recent) model or a full model breakdown. Trigger when asked for model-level usage/cost data from codexbar, or when you need a scriptable per-model summary from codexbar cost JSON.
arscontexta
2.9kClaude Code plugin that generates individualized knowledge systems from conversation. You describe how you think and work, have a conversation and get a complete second brain as markdown files you own.
