Arcadedb
ArcadeDB Multi-Model Database, one DBMS that supports SQL, Cypher, Gremlin, HTTP/JSON, MongoDB and Redis. ArcadeDB is a conceptual fork of OrientDB, the first Multi-Model DBMS. ArcadeDB supports Vector Embeddings.
Install / Use
/learn @ArcadeData/ArcadedbREADME
ArcadeDB is a Multi-Model DBMS created by Luca Garulli, the same founder of OrientDB, after SAP's acquisition. Written from scratch with a brand-new engine made of Alien Technology, ArcadeDB is able to crunch millions of records per second on common hardware with minimal resource usage. ArcadeDB reuses OrientDB's SQL engine (heavily modified) and some utility classes. It's written in LLJ: Low Level Java - still Java21+ but only using low level APIs to leverage advanced mechanical sympathy techniques and reduce Garbage Collector pressure. Highly optimized for extreme performance, it runs from a Raspberry Pi to multiple servers on the cloud.
ArcadeDB is fully transactional DBMS with support for ACID transactions, structured and unstructured data, native graph engine (no joins but links between records), full-text indexing, geospatial querying, and advanced security.
ArcadeDB supports the following models:
- Graph Database (compatible with Neo4j Cypher, Apache Tinkerpop Gremlin and OrientDB SQL)
- Document Database (compatible with the MongoDB driver + MongoDB queries and OrientDB SQL)
- Key/Value (compatible with the Redis driver)
- Search Engine
- Time Series (with InfluxDB Line Protocol, Prometheus remote_write/read, and PromQL support)
- Vector Embedding
- Geospatial
ArcadeDB understands multiple languages:
- SQL (from OrientDB SQL)
- Neo4j Cypher (Open Cypher)
- Apache Gremlin (Apache Tinkerpop v3.7.x)
- GraphQL Language
- MongoDB Query Language
ArcadeDB key capabilities:
- 70+ Built-in Graph Algorithms — Pathfinding, centrality, community detection, link prediction, graph embeddings, and more — all available out of the box
- Parallel Query Execution — SQL queries leverage multiple CPU cores for faster execution on large datasets
- Materialized Views — Pre-computed query results stored and automatically maintained
- MCP Server — Built-in Model Context Protocol server for AI assistant and LLM integration
- AI Assistant — Integrated AI assistant in Studio (Beta) for query help and database management
- Geospatial Indexing — Native spatial queries and proximity searches with
geo.*SQL functions - TimeSeries — Columnar storage with Gorilla/Delta-of-Delta compression, InfluxDB/Prometheus ingestion, PromQL queries, Grafana integration
- Hash Indexes — Extendible hashing for faster exact-match lookups alongside LSM-Tree indexes
ArcadeDB can be used as:
- Embedded from any language on top of the Java Virtual Machine
- Embedded from Python via bindings: arcadedb-embedded-python
- Remotely by using HTTP/JSON
- Remotely by using a Postgres driver (ArcadeDB implements Postgres Wire protocol)
- Remotely by using a Redis driver (only a subset of the operations are implemented)
- Remotely by using a MongoDB driver (only a subset of the operations are implemented)
- By AI assistants via the built-in MCP Server (Model Context Protocol)
For more information, see the documentation.
Use Cases
Explore real-world examples in the arcadedb-usecases repository — self-contained projects with Docker Compose, SQL schemas, and runnable demos covering:
- Recommendation Engine — graph traversal + vector similarity + time-series
- Knowledge Graphs — co-authorship and citation networks with full-text search
- Graph RAG — retrieval-augmented generation with LangChain4j and Neo4j Bolt
- Fraud Detection — graph, vector, and time-series signals with Cypher
- Real-time Analytics — IoT and service monitoring with time-series
- Social Network Analytics — materialized view dashboards with polyglot queries
- Supply Chain — multi-tier visibility with PostgreSQL protocol and JavaScript
Getting started in 5 minutes
Start ArcadeDB Server with Docker:
docker run --rm -p 2480:2480 -p 2424:2424 \
-e JAVA_OPTS="-Darcadedb.server.rootPassword=playwithdata -Darcadedb.server.defaultDatabases=Imported[root]{import:https://github.com/ArcadeData/arcadedb-datasets/raw/main/orientdb/OpenBeer.gz}" \
arcadedata/arcadedb:latest
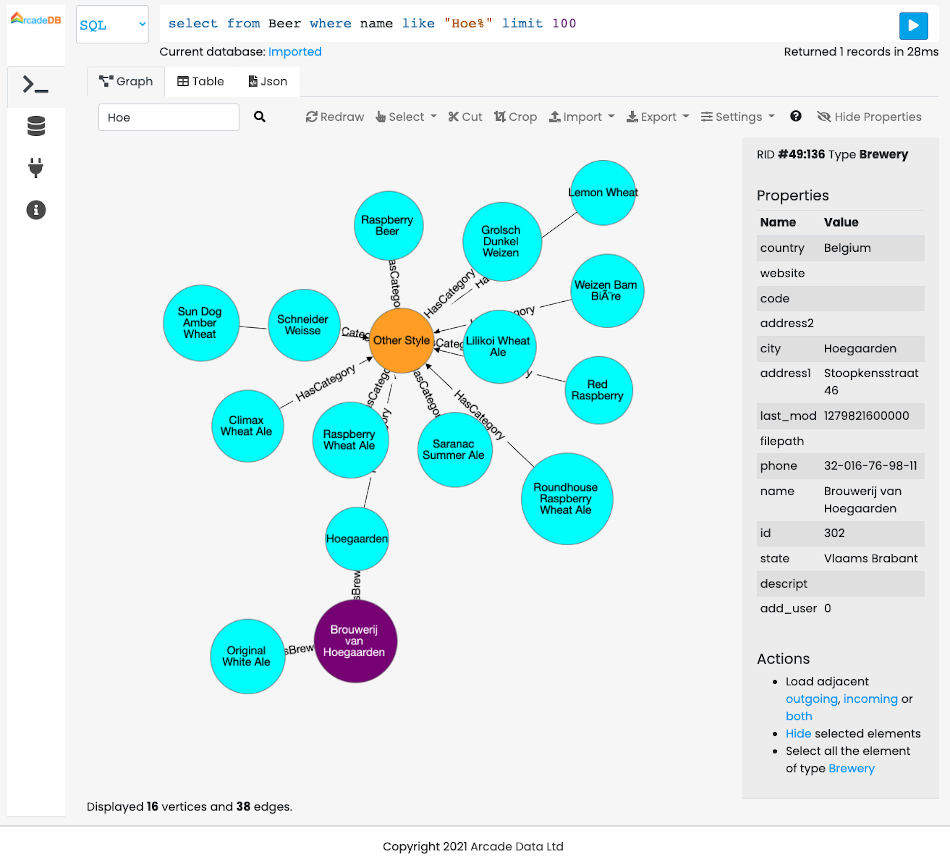
Now open your browser on http://localhost:2480 and play with ArcadeDB Studio and the
imported OpenBeer database to find your favorite beer.
ArcadeDB is cloud-ready with Docker and Kubernetes support.
You can also download the latest release, unpack it on your local hard drive and start the server with bin/server.sh or bin/server.bat for Windows.
Releases
There are four variants of (about monthly) releases:
full- this is the complete package including all modulesminimal- this package excludes thegremlin,redisw,mongodbw,graphqlmodulesheadless- this package excludes thegremlin,redisw,mongodbw,graphql,studiomodulesbase- core engine, server, and network only — excludes all optional modules (`consol
