SuperMachineLearningNotes
Super-Machine-Learning-Revision-Notes
Install / Use
/learn @AlphaOneSrc/SuperMachineLearningNotesREADME
内容目录
激活函数
函数 | 表达式 | 导数 --- | --- | --- sigmoid | $g(z) = \frac{1 }{ 1 + e^{(-z)}}$ | $g(z)(1- g(z))$ tanh | $ tanh(z)$ | $ 1 - (tanh(z))^2 $ Relu | $max(0,z)$ | $ 0,if (z < 0) \ 未定义, if (z = 0) \ 1, if (z > 0) $ Leaky Relu | $max (0.01z,z)$ | $0.01,if (z < 0) \ 未定义, if (z = 0) \ 1 ,if (z > 1)$
常见的激活函数包括三类:
- S型曲线
- 修正线性单元(ReLU)
- Maxout单元
激活函数需要具备的特点:
- 连续并可导的非线性函数,可导的激活函数可以直接利用数值优化的方法来学习网络参数
- 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率
- 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和温度性
梯度下降
梯度下降是求解目标函数局部最小值的一种迭代方法(如损失函数),其迭代的过程如下:
Repeat{
W := W - learning_rate * dJ(W)/dW
}
符号$:=$表示覆盖操作。从公式中可以看出,在梯度下降求解过程中要不断的去更新$W$
通常用$\alpha$表示学习率,当训练神经网络时,它是一个很重要的超参数(更多关于超参数的介绍可参考下一节)。$J(W)$表示模型的损失函数,$ \frac{d J(W)}{d(W)} $是关于参数$W$的梯度,如果参数$W$是个矩阵,则$ \frac{d J(W)}{d(W)} $也会是一个矩阵。
问题:为什么我们在最小化损失函数时不是加上梯度?
答:假设损失函数是$J(W)=0.1 (W-5)^2$,如下图所示:
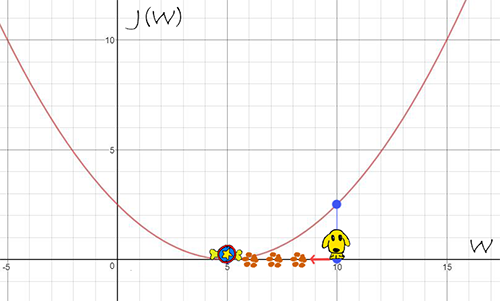
当参数$W=10$时,梯度$ \frac{d J(W)}{d(W)} = 0.1 * 2 (10-5) = 1$,很显然,如果继续寻找最小的损失函数$J(W)$时,梯度的反方向(eg:$-\frac{d J(W)}{d(W)} $)是找到局部最优点的正确方向(eg:$J(W=5)=0$)。
但需要注意的是,梯度下降法有时候会遇到局部最优解问题。
计算图
计算图的例子在Deep Learning AI的第一节课程中被提到。
假设有三个可学习的参数$a,b,c$,目标函数定位为:$J=3(a + bc)$,接下来我们要计算参数的梯度:$\frac {dJ}{da},\frac {dJ}{db},\frac {dJ}{dc}$,同时定义$u = bc,v = a+u,J =3v$,则计算过程可以转化为下边这样的计算图。
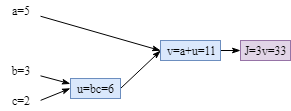
反向传播算法
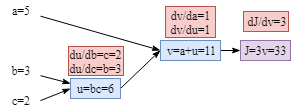
从上图可以看出,参数的梯度为:$\frac {dJ}{da} = \frac{dJ}{dv} \frac {dv}{da}, \frac {dJ}{db} =\frac {dJ}{dv}\frac {dv}{du}\frac {du}{db}, \frac {dJ}{dc} =\frac {dJ}{dv}\frac {dv}{du}\frac {du}{dc} $。
计算每个节点的梯度比较容易,如下所示(这里需要注意的是:如果你要实现自己的算法,梯度可以在正向传播时计算,以节省计算资源和训练时间,因此当反向传播时,无需再次计算每个节点的梯度)。
现在可以通过简单的组合节点梯度来计算每个参数的梯度。
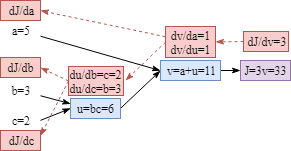
$\frac {dJ}{da} = \frac{dJ}{dv} \frac {dv}{da} = 3* 1 = 3$
$\frac {dJ}{db} =\frac {dJ}{dv}\frac {dv}{du}\frac {du}{db} = 3 * 1 * 2 = 6$
$\frac {dJ}{dc} =\frac {dJ}{dv}\frac {dv}{du}\frac {du}{dc} = 3 * 1 * 3 = 9$
L2正则修正的梯度(权重衰减)
通过引入 $\frac {\lambda}{m} W$ 改变梯度的值。
Repeat{
W := W - (lambda/m) * W - learning_rate * dJ(W)/dW
}
梯度消失和梯度爆炸
如果我们定义了一个非常深的神经网络且没有正确初始化权重,可能会遇到梯度消失或梯度爆炸问题(更多关于参数初始化的可以参考:参数初始化。
这里以一个简单的但是深层的神经网络结构为例(同样,这个很棒的例子来自于线上AI课程:Deep Learning AI)来解释什么是梯度消失,梯度爆炸。
假设神经网络有$L$层,为了简单起见,每一层的参数$b^l$为0,所有的激活函数定义为:$g(z)=z$,除此之外,每层的连接权重$W^l$拥有相同的权重:$W^{[l]}=\left(\begin{array}{cc} 1.5 & 0\ 0 & 1.5 \end{array}\right)$。
基于上述的简单网络,最终的输出可能为: $y=W^{[l]}W^{[l-1]}W^{[l-2]}…W^{[3]}W^{[2]}W^{[1]}X$
如果权重$W=1.5>1$,$1.5^L$将会在一些元素上引起梯度爆炸。同样,如果权重值小于1,将会在一些元素上引起梯度消失。
梯度消失和梯度爆炸会使模型训练变得十分困难,因此,正确初始化神经网络的权重十分重要。
小批量梯度下降
如果训练集数据特别大,单个batch在训练时会花费大量的时间,这对开发者而言,跟踪整个训练过程会变得十分困难。在小批量梯度下降中,根据当前批次样本计算损失和梯度,在一定程度上能够解决该问题。
$X$代表整个训练集,它被划分成下面这样的多个批次,m表示的是训练集的样本数。
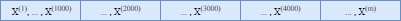
小批量梯度训练的过程如下:
For t= (1, ... , #批次大小):
基于第t个批次进行前向传播计算;
计算第t个批次的损失值;
基于第t个批次进行反向传播计算,以计算梯度并更新参数.
在训练过程中,对比不应用小批量梯度下降和应用小批量梯度下降,前者下降的更加平滑。
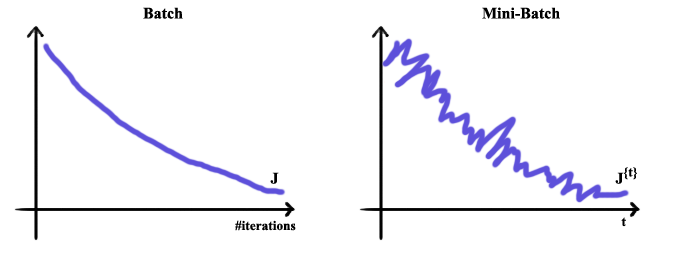
随机梯度下降
随机梯度下降时,批次的样本数大小为1。
小批量梯度下降批次大小选择
小批量大小:
- 如果批次大小为M,即整个训练集的样本数,则梯度下降恰好为批量梯度下降
- 如果批次大小为1,则为随机梯度下降
实际应用中,批次大小是在$[1,M]$之间选择。如果$M \leq 2000$,该数据集是一个小型数据集,使用批量梯度下降是可以接受的。如果$M > 2000$,使用小批量梯度下降算法训练模型更加适合。通常小批量的大小设置为:64,128,256等。
下图为使用不同批次大小训练模型的下降过程。
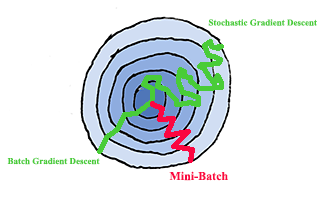
Momentum
神经网络中普遍使用的是小批量梯度下降优化算法,因此这里介绍的Momentum和下边介绍的RMSprop,Adma都是结合小批量梯度下降优化进行的。
增加动量法小批量梯度第$t$次迭代过程如下:
- 基于当前的批次数据计算$dW,db$
- $V_{dW}=\beta V_{dW}+(1-\beta)dW$
- $V_{db}=\beta V_{db}+(1-\beta)db$
- $W:=W-\alpha V_{dW}$
- $b:=b-\alpha V_{db}$
动量法中的超参数为$\alpha, \beta$。在动量法中,$V_{dW}$是上一个批次的历史梯度数据。如果令$\beta=0.9$,这意味着要考虑最近10次迭代的梯度以更新参数。
$\beta$原本是来自指数加权平均值的参数。例如:$\beta=0.9$意味着取最近10个值作为平均值,$\beta=0.999$意味着考虑最近1000次的结果。
RMSprop
RMSprop的全称是Root Mean Square Prop,
在RMSprop优化算法下,第$t$个批次的迭代过程如下:
- 基于当前的批次数据计算$dW,db$
- $S_{dW}=\beta S_{dW}+(1-\beta)(dW)^2$
- $S_{db}=\beta S_{db}+(1-\beta)(db)^2$
- $W:=W -\alpha \frac{dW}{\sqrt{S_{dW}}+\epsilon}$
- $b:=b-\alpha \frac{db}{\sqrt{S_{db}}+\epsilon}$
Adma
Adma全称是Adaptive Moment Estimation,自适应动量估计算法。可以看作是动量法和RMSprop的结合,不但使用动量作为参数更新,而且可以自适应调整学习率。
$V_{dW}=0, S_{dW=0},V_{db}=0, S_{db}=0$
在Adma优化算法下,第t个批次的迭代过程如下:
1). 基于当前的批次数据计算$dW,db$
// 动量法
2). $V_{dW}=\beta_1 V_{dW}+(1-\beta_1)dW$
3). $V_{db}=\beta_1 V_{db}+(1-\beta_1)db$
// RMSprop
4). $S_{dW}=\beta_2 S_{dW}+(1-\beta_2)(dW)^2$
5). $S_{db}=\beta_2 S_{db}+(1-\beta_2)(db)^2$
// 偏差校正
6). $V_{dW}^{correct}=\frac{V_{dW}}{1-\beta_1^t}$
7). $V_{db}^{correct}=\frac{V_{db}}{1-\beta_1^t}$
6). $S_{dW}^{correct}=\frac{S_{dW}}{1-\beta_2^t}$
7). $S_{db}^{correct}=\frac{S_{db}}{1-\beta_2^t}$
// 参数更新
$W:=W -\alpha \frac{V_{dW}^{correct}}{\sqrt{S_{dW}^{correct}}+\epsilon}$
$b:=b-\alpha \frac{V_{db}^{correct}}{\sqrt{S_{db}^{correct}}+\epsilon}$
"纠正"是指数加权平均的偏差校正的概念。纠正使得平均值的计算更加准确。$t$是$\beta$的幂。
通常,超参数的值为:$\beta_1 = 0.9$,$\beta_2 = 0.99$,$\epsilon=10^{-8}$
学习率$\alpha$需要进行调整的,当然也可以使用学习率衰减的方法,同样可以取得不错的效果。
学习率衰减
如果在训练期间固定学习率,如下图所示,损失或者目标可能会波动。因此寻找一种具备自适应调整的学习率会是一个很好的方法。
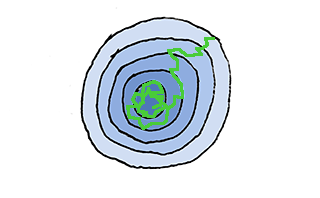
基于Epoch的衰减

根据epoch的值来降低学习率是一个直接方法,其衰减方程如下: $$ \alpha=\frac{1}{1+DecayRate*EpochNumber}\alpha_0 $$
其中 DecayRate是衰减率,EpochNumber表示epoch的次数。
例如,初始学习率$\alpha=0.2$,衰减率为1.0,每次epoch的学习率为: Epoch | $\alpha$ ----| --- 1 | 0.1 2 | 0.67 3 | 0.5 4 | 0.4 5 | ...
也有一些其他的学习率衰减方法,如下:
方法 | 表达式
--- | ---
指数衰减 | $\alpha=0.95^{EpochNumber}\alpha_0$
基于epoch次数的衰减 | $\alpha=\frac{k}{EpochNumber}\alpha_0$
基于批量大小的衰减 | $\alpha=\frac{k}{t}\alpha_0$
“楼梯”衰减 | 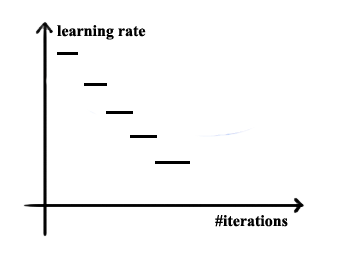 手动衰减 | 按照天或者小时手动衰减降低学习率
手动衰减 | 按照天或者小时手动衰减降低学习率
批量归一化
训练时批量归一化
批量标准化可以加快训练速度,步骤如下:

每个层$l$中,归一化的具体公式如下:
$\mu=\frac{1}{m}\sum Z^{(i)}$
$\delta^2=\frac{1}{m}\sum (Z^{(i)}-\mu)$
$Z^{(i)}_{normalized}=\alpha \frac{Z^{(i)}\mu}{\sqrt{\delta^2}+\epsilon} +\beta$
$\alpha, \beta$是可学习的参数。
测试时批量归一化
在测试时,因为每次可能只有一个测试的实例样本,所以没有充足的实例样本计算$\mu$ 和 $\delta$。
在这种情况下,最好使用跨批量的指数加权平均值来估计$\mu$ 和 $\delta$的合理值。
参数
可学习参数和超参数
可学习参数
$W,b$
例如 一元一次方程 $ y = Wx + b$ 中的 $W,b$ 就是根据训练集自学习的参数。在神经网络中,$W$通常表示权重向量$[w_1, w_2...,w_n]$,$b$通常表示偏置。
超参数
- 学习率 $\alpha$
- 迭代次数
- 神经网络层数$L$
- 隐藏层每一层的单元个数
- 激活函数
- 动量法的参数
- 小批量梯度下降优化算法的批大小
- 正则化参数
神经网络采用的是小批量梯度下降优化算法。动量法是梯度下降方向优化的方法。
参数初始化
小值初始化
在初始化参数$W$时,通常将其初始化为比较小的值。比如在Python中这样实现:
W = numpy.random.randn(shape) * 0.01
进行小值初始化的原因是,当使用的激活函数为Sigmoid时,如果权重过大,在进行反向传播计算时会导致梯度很小,可能引起梯度消失问题。
结合网络单元数的小值的权重初始化
同样,我们使用伪代码的方法表示各种初始化的工作方式。当隐藏层网络单元的个数很大时,更加倾向于使用较小的值进行权重初始化,防止训练时梯度消失或梯度爆炸。如下图这样:
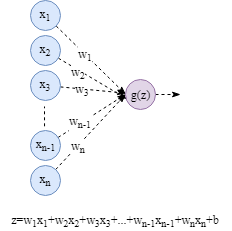
基于上述的思路,可以结合隐藏层单元的个数对权重进行初始化,Python表达如下:
W = numpy.random.randn(shape) * numpy.sqrt(1/n[l-1])
其对应的数学表达式为:$ \sqrt {\frac {1 }{n^{l-1}}}$,$n^{l-1}$表示第$l-1$层的神经元个数,如果选用的是ReLU激活函数,对应的数学表达式为:$ \sqrt {\frac {2 }{n^{l-1}}}$。
Xavier初始化
如果在神经网络中你使用的激活函数是tanh,使用Xavier进行权重初始化能够取得不错的效果,Xavier的公式如下:$\sqrt { \frac{1 }{ n^{l-1}} }$或者$\sqrt { \frac{ 2 }{ n^{l-1} + n^l} }$(其中$n^{l-1}$表示第$l-1$层的神经元个数,$n^l$表示第$l$层的神经元个数)。
不同文献中 Xavier初始化的表达式不同,但大同小异,改变的只是根号下分子部分,最终不会改变参数的分布。
超参数调优
当训练超参数时,尝试参数所有的可能取值是必要的,如果在资源允许的情况下把不同的参数值传给同一个模型进行并行训练是最简单的方法。但是事实上,资源是很有限的,在这种情况下,同一时间,我们只能训练一个模型,并在不同时间尝试不同参数。
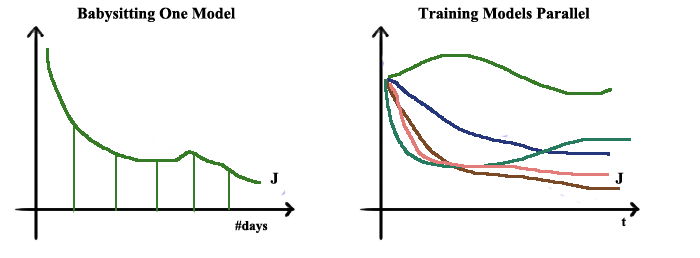
除了上述介绍的,如何选择合适的超参数也是非常重要的。
在神经网络中都很多超参数,比如:学习率$\alpha$,动量法和RMSprop的参数($\beta _1,\beta _2,\epsilon$),神经网络层数,每一层的单元数,学习率衰减参数,批训练的批大小。
Andrew Ng提出了相关参数的优先级,如下: 优先级 | 超参数 --- | --- 1 | 学习率$\alpha$ 2 | $\beta _1,\beta _2,\epsilon$(动量法和RMSprop的参数) 2 | 隐藏层单元数 2 | 批训练的批大小 3 | 网络层数 3 | 学习率衰减系数
通常默认的动量法和RMSprop的参数为:$ \beta _1 = 0.9, \beta _2 = 0.99,\epsilon = 10^{-8} $
隐藏层和网络单元的均匀采样
例如,神经网络层范围是[2,6],我们可以均匀的尝试2,3,4,5,6去训练模型。同样网络单元范围是[50,100],在这个范围内进行尝试也是一个好的策略。表示如下:
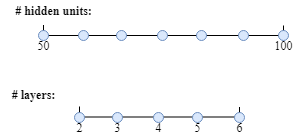
对数采样
或许,你已经意识到均匀采样对于所有类型的参数不是一个好方法。
例如,我们认为学习率$\alph

Security Score
Audited on Jan 6, 2026